最近在整理文本挖掘
最近事情很多,每天下班回来,自己弄些东西吃,稀里糊涂就到了21点。跟着再浏览一下圈子信息,时间更是倏地一下就到了0点,然后第二天变熊猫……
主要在忙两件事
- 翻译《R in a nutshell》,三月底应该会到出版社那边
- 重头戏,整理文本挖掘的相关技术
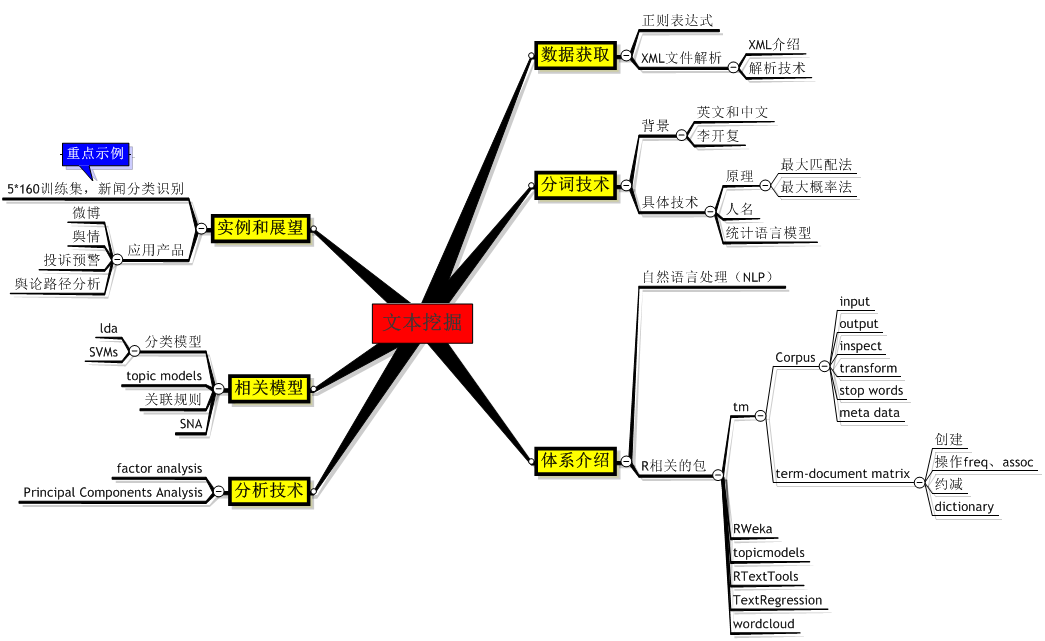
明天会在公司内部进行文本挖掘的培训,下面是提纲:
说到文本挖掘,就要说一下文本云可视化。前一段时间老觉得wordcloud这个包的可视化图形不是很美观,于是想重写这个包。但随着深入理解文本云,发现非常不简单,是个NP问题,一时半会没有太好的处理办法。从实际项目的角度,这种可视化意义不是很大,几经折腾后无奈放弃。
但这其中的折腾还是蛮有意思的,比如最初的想法是可以绘制任意形状的文本云,比如根据中国地图形状(但太丑了,又放弃):

还有类似这样效果的:
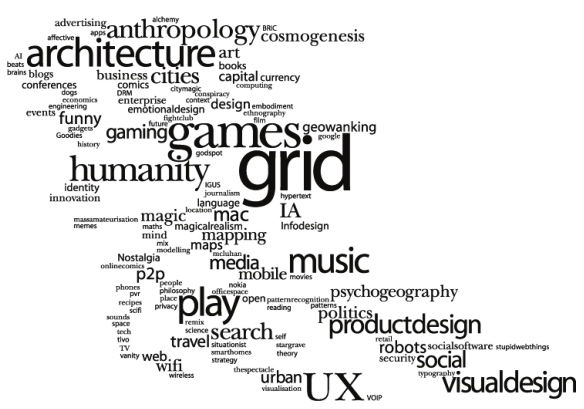
有时间再搞吧——但有时间的话就应该在图像识别这块了,囧!