R 语言企业级数据挖掘应用
三月底参加了中国人民大学统计学院海峡两岸数据挖掘研讨会,和大家简单聊了聊R语言在京东商城的数据挖掘应用。本来想接着写篇博文说明一下, 一直也没腾出时间,今天补上。
1. 为什么要使用R语言
在互联网企业,在分析端使用闭源的商用软件几乎是不可能的,原因很简单:成本太高,不管是使用,还是研发及维护。 但我个人觉得这可能还不是最主要的原因,对于互联网企业来说,数据虽然获取更容易,但环境更为复杂。开源软件可以根据业务的变化 进行调整,但商业的闭源软件则很难做到。
2. R能不能处理大数据
好多人问过我这个问题,我会说你有多大内存就能处理多大数据,这话显然不负责任。这个问题确实不太好回答,因为每个人心中的大数据是不一样的。 比如有人觉得几百万就是大数据,有些人觉得没个几亿就不算大数据,甚至有人说你处理不了的就是大数据(擦!?)。这些还只是从记录 数(数据存储)的角度来看的,我们换个角度想想:建模工程师要做的事情无非是将用户和产品进行合理匹配,那最细粒度就是用户维(或产品维)。 试问你有超过千万的用户数据分析建模么?对于一般的分析(工程)师来说,常见的情况还是几十万甚或百万级别。这个量级对于R来说就很容易了, 比如我刚刚的工作就是在自己的PC上载入了一个50000000×3的数据框。
接着我们在说说速度,曾经有太多的人抱怨R的运行速度太慢,甚至堂而皇之的公开表明观点。但我发现大部分人是因为不熟悉R语言的编程, 而是直接套用C或Java的编程方式,因而导致无法快速得到结果。举两个例子:
有次在微博上一位朋友抱怨说R做了一个几千乘几千的相关矩阵花了他1天时间,我当时就愕然了,然后默默地给了一个几秒钟搞定的脚本。
还有一次更具有代表性:我的项目组有个R的项目需要上线,于是直接把原始代码交予了一位项目成员,嘱咐他稍作改动即可上线。 但他发现需要3个小时才能将线上的数据计算完毕,于是又找到我帮忙优化。我看了一下,果不其然,Java风格的R代码,向量化编程的思想 一点都没有用。改之,3分钟结束计算。
R语言的向量化运算几乎可以和底层语言的速度一较高下,并且向量化是天然的并行化方式,如果条件允许,R的向量化编程可以很方便的转化为并行框架,
这也就是为什么说R + Hadoop是大数据的发展方向的理由之一。
再说个例子:试问100万行,20万列的数据是大数据么(你没看错,是200000维)?恩,R能够处理,而且可以在这类数据上构建模型。
3. 再看看大数据的流动
对于管理者来说,合适的人出现合适的岗位是衡量管理者是否合格的重要标准之一。对于数据分析人员,合适的工具匹配合适的数据则是是否胜任工作的 基本素质之一。R并不是通吃所有的数据场景,它只是在出现在该出现的分析建模环节。
R的位置在哪里?先让我们看看所谓的大数据是如何从企业中传递的(摘自本次人大的演讲材料)
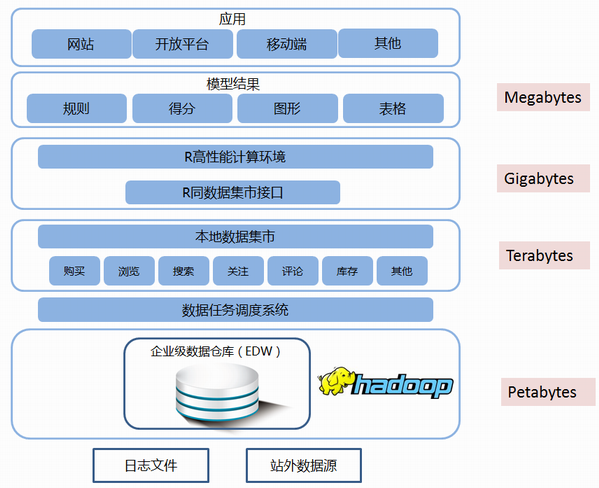
- 从最底层的原始数据来看,PB级数据确实不是R所擅长,但这些数据有Hadoop或者其他高性能存储和处理系统;
- 向上是针对于不同业务场景的数据集市,经过清洗后,数据的规模则下降到了TB级;
- 再向上则是针对于特定任务的分析和挖掘模块,数据已经被整理到了GB级,这时候R的处理则是非常方便
- R分析的结果则是MB级的输出,比如图表、得分,或者是规则。比如规则很容易在数据集市这段做并行化计算
我的团队在大量使用R作为分析建模工具,看似比较另类,但其实Google、Facebook、Linkedin等公司已经有大量的直接使用R做分析挖掘的应用, 只是大家不太留意罢了。
一句话总结:R并不是在象牙塔里供科研人员玩耍的玩具,而是实实在在工业界使用的便捷环境。
当然,这里还有很多问题没有展开,比如:
- R语言的数据挖掘应该在并行化环境完成还是在单台机器的计算环境完成?
- 抽样可否解决大数据挖掘问题?
- 生产中直接实施R环境是否可行?
我们有时间再聊~
附下载:R语言数据挖掘@京东商城