喜欢的商品怎么找到你
业务背景
出于用户体验、吸引用户角度的考量,经过多年发展,推荐系统其实已经在各类型网站或app上称为标准服务,不论是新闻、音乐、电商、电影等内容。当然,通过人工编辑也可以形成简单的推荐引擎,但这种方式的效率非常低,且比较生硬。如何通过用户的行为自动化地产生适合清单,是我们一直追求的目标。
设想一下:你现在正在登录到 JD.com(京东),虽然我们拥有海量的商品可供选择,但你可能正在漫无目的的闲逛;也有可能是昨天秒杀了一件商品,回到京东正在回味自己的英明决策;或者最近几款新式手机上市,你正在兴致勃勃的对比参数性能……
一万个读者有一万个哈姆雷特,一亿个用户就有一亿个京东
“一亿个京东”背后强有力的支持便是推荐系统。在京东Web、app、微信、手机QQ等各个环节均会存在商品推荐。贯穿了用户全流程购物环节,包括首页、商品详情页、购物车、我的京东等。
为了具象化这个问题,我们可以简单认为这个位置是我们网购流程中的购物车环节。出于方便用户更好的找到心仪的商品,我们提供了“为你推荐”模块。
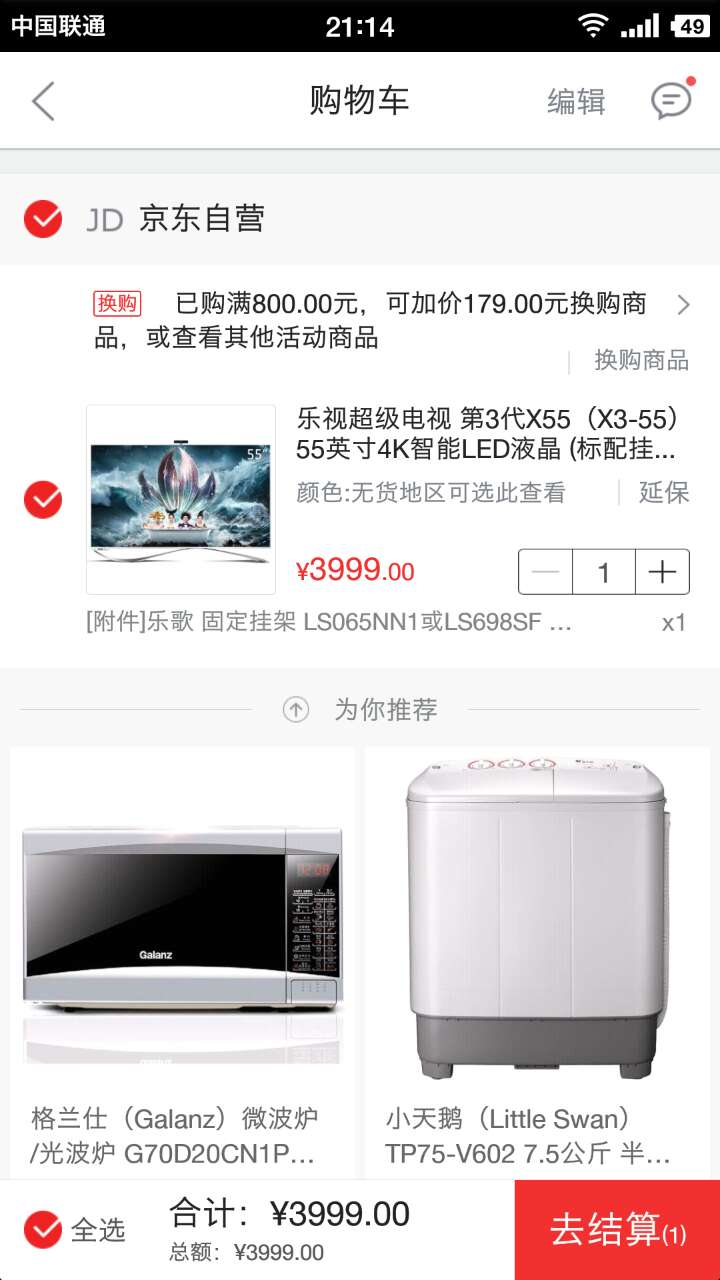
问题很简单了,用户将这个商品加入购物车之后,在下面有限的位置(用户下拉浏览商品有限),如何在不影响自身商品成交的基础上,用户购买的商品更多?比如在上面的示例中,我们希望用户购买乐视X55超级电视后,同时购买格兰仕微波炉和小天鹅7.5公斤半自动洗衣机。
数据介绍和描述
在阐述数据之前,我们先停下脚步思考一下为用户提供购物车“为你推荐”模块应该关注的几个问题。
关注的问题
- 谁会看这个模块?他们为什么会看到这个模块?
- 哪些信号可以被我们捕捉到?如果没有,我们可否再增加?
- 在触发这个模块时,用户的profile和实时兴趣是什么?
- 有什么可能的商品候选集可以提供给用户挑选?
- 我们给出的候选集是否有“不怀好意”的作弊呢?
- 用户的注意力有限,提供出来的__商品候选集Top N是如何计算的?__
- 为什么用户看到了,却没有购买,甚至连点击也没有?
- ……
以上关注要点,每个都需要专门的数据分析师或算法工程师做独立回答。任何一个问题没有完整答案,都会影响单位流量的效果。但篇幅所限,我们仅仅来讲讲最核心的问题
如何计算商品候选集的Top N
相关的数据
京东通过自行设计的点击流系统来完整记录用户行为,这套点击流系统非常灵活,我们可以随时变更记录的内容,以适应业务需求的变化。
点击流的记录可以简单的理解由用户、时间、事件、来源事件四部分组成,同时匹配事件的attribute,我们就可以记录所有用户感兴趣的内容,以及内容之间的关联。需要强调的是,点击流数据不但用于在离线端进行数据建模,同时也可以进行实时消费。
在用户喜欢商品Top N这个问题上,通过点击流,我们可以轻易的收集到以下信息:
- 用户在网站上的完整浏览路径,包括商品点击,活动页面,进入购物车页面、结算页。
- 用户购买商品之后主动在网站提交的评论信息
- 用户的搜索行为
以及用户感知不到的,商品的类目和属性信息(比如促销信息),甚至是我们通过离线或近线系统挖掘出来的商品信号。以上信息全部会转化为可度量的数据。
数据建模和评估
和传统的数据挖掘项目不同,这个业务场景是在线上实时部署的。公开数据显示:页面如果延迟1秒会造成74%用户离开。因此我们必须能够在毫秒级对用户的行为作出反应。为此我们设计了以下两个步骤:
- 初步(一阶段)排序:对用户可能喜欢的结果,做多召回结果的线性融合,优化目标同时考虑点击率和转化率
- 精确(二阶段)排序:引入用户的个性化行为,对融合结果再次重排,目标为转化率和销售金额
离线建模之后,评估模型的好坏使用MSE和NDCG指标来评判。但我们更关心线上的表现,因此最终关注指标实际为千次请求订单行(rCVR)、UV价值和RPM。
初步排序
依然以用户进入购物车为例,假如你进入购物车,我们的点击流系统已经记录了你看过什么商品、搜索过什么关键词、前两天买过什么、刚刚加入购物车的商品、购物车里有什么、你的实时兴趣是什么……
当然,我们根据其他用户过往的记录计算:
- 用户看了商品之后还会看什么商品(\(R_i\))
- 买这个商品的同时还会买什么(\(I_i\))
- 买过这个商品之后几天还会买什么(\(T_i\))
- 和这个商品相似的商品还有什么(\(S_i\))
- 搜索该商品之后还会搜什么(\(Q_i\))
- 看了这个商品之后还会买什么(\(P_i\))
- 有这个实时兴趣的用户会买什么(\(G_i\))
以上的结果全部是可能给你推荐的商品。我们希望提供给用户的候选集尽可能的多,即表示为
\[ w_1 R + w_2 I + w_3 T + w_4 S + w_5 Q + w_5 P + w_6 G \]
在这个过程中需要尽可能精简的获取到召回结果,因此在融合的过程中对有些召回做了惩罚,即每个类型的召回权重 \(w_i\) 做惩罚,甚至有些用户行为召回商品的权重需要压缩为零。
通过LASSO或弹性网可以将模型的系数进行压缩,优化目标同时考虑点击率和转化率,模型融合问题可以抽象为:
观测值 \(x_i \in \mathbb{R}^p\) 和响应变量 \(y_i \in \mathbb{R}, i = 1, \ldots, N\)。目标函数为
\[ \min_{(\beta_0, \beta) \in \mathbb{R}^{p+1}}\frac{1}{2N} \sum_{i=1}^N (y_i -\beta_0-x_i^T \beta)^2+\lambda \left[ (1-\alpha)||\beta||_2^2/2 + \alpha||\beta||_1\right], \]
这里 \(\lambda \geq 0\) 是一个复杂性参数,\(0 \leq \alpha \leq 1\) 压缩参数,限制在 RIDGE (\(\alpha = 0\)) 和 LASSO (\(\alpha = 1\))之间。
通过这个步骤的建模,有些用户的行为权重会被降低权重,甚至忽略。且融合结果最优配置了所有已知数据源。
一阶段排序可以完全通过离线训练以及预测,线上调用只需要进行Key-Value获取即可。如果有业务需要,也可以并通过配置,进行线上各数据源的mix。
精确排序
初步排序解决的实际是群体用户的泛化行为的总结问题,接下来我们需要再引入用户的个性化信号,进行二阶段精确排序。
对于用户层级,我们拥有每个用户的PROFILE和实时兴趣两种类型信号。 用户PROFILE可以理解为DEMOGRAPHIC类型数据,实时兴趣可以理解为实时信号的累加,比如品牌兴趣、价格等级强度等。
很容易将用户的这两种类型数据和商品进行连接:如果你实时体现的喜欢A品牌,A品牌(或A相关品牌)会特意地提前。这个步骤可以通过转化为标准的CTR预测问题来解决:
- 数据清洗:目的是对日志文件中的缺失值、错误数据以及前后记录格式不一致的数据进行处理。比如因为终端问题,用户由于未登录会导致很多数据无法记录,通过设备唯一标识号可以连接有效的用户行为。
- 数据转换和集成:数据转换是指对数据进行平滑、特征计算、数据统计等;数据集成是指通过唯一ID将多个数据源的数据连接到一起。
- 用户行为标注:行为标注在数据预处理环节是最重要的一环,目的是甄别出用户每一个浏览/加入购物车/关注等动作对商品的感兴趣程度。 我们会按照时间尺度的大小分别对用户的进行兴趣识别——在较大的时间尺度上(比如以“天”为单位),会看用户这次浏览行为是否为“已购买商品的查单行为(查看已购买商品所在分类的其他商品,或者是已购买商品本身)”,或者是到了购买周期,需要重新购买该品类的商品等情形;较小时间尺度上,比如用户 SESSION 级别,我们会研究用户的浏览路径,确切说在商品页是否触发了某些“事件”,比如用户是否查看了商品的评论、规格参数、售后保障等,或者是否触发了页面底端的某些事件等;另外在用户的浏览路径中也会突然出现多个不同品类的商品,这些行为是用户的真实兴趣或者是被某些其他事件的吸引,也会进行标注。
- 数据归一:数据中所有字段或者属性之间必须有一个统一的计量单位或者相同的范围。统一量纲会使得计算的特征有可比性。
排序预测上,我们使用了Gradient Boosting Machines。假设我们有K棵树,预测的最终模型为:
\[ \hat{y_i} = \sum_{k=1}^K f_k(x_i) \]
在这里\(f_k\)是第\(k\)棵树的预测结果。
考虑Logloss损失以及正则化,我们优化目标为
\[ Obj = L+\Omega = \sum_{i=1}^N L(y_i,\hat{y}_i^{(t)})+\sum_{i=1}^t \Omega(f_i) = \sum_{i=1}^N L(y_i,\hat{y}_i^{(t-1)}+f_t)+\sum_{i=1}^t \Omega(f_i) \]
在这里\(\Omega = \gamma T + \frac{1}{2}\lambda \sum_{j=1}^{T} w_j^2\),\(T\)是叶子节点个数,\(w\)是节点的权重。考虑惩罚项的主要因也是出于性能方面的考虑,我们希望使用最少的特征对线上结果进行重排序。
业务实施
线上过程我们使用一套被称为RankFlow的框架来执行。除上面的排序流程外,还有信息补全以及过滤等环节均由RF来执行。通过工程师的持续性能优化,1000次这样的推荐请求,999次的响应时间控制在200毫秒以下,基本不会对用户的感知有任何影响。
为了验证排序学习的有效性,我们对几类排序学习进行了线上流量的 AB Test 测试,在使用相同的召回源条件下,
- 人工经验排序(主要是策略和规则)
- 融合模型
- 二次排序
三个实验在观察的时间段(11天)时序表现如下:
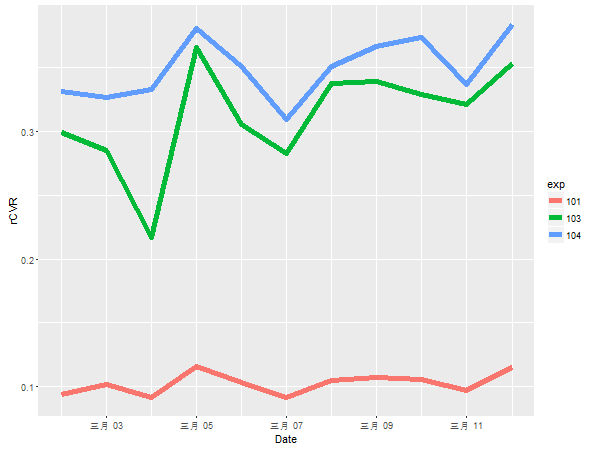
各组实验的指标均值体现:
| 序号 | 实验号 | rCVR指标11天均值(%) | 说明 |
|---|---|---|---|
| 1 | 101 | 0.1025762 | 人工规则 |
| 2 | 103 | 0.3124554 | 线性融合 |
| 3 | 104 | 0.3494676 | 二次排序 |
总结讨论
本文单独针对于商品推荐中的如果选取TopN商品问题做了详细的论述,大部分触发式推荐均可以按照这个方案处理,在使用以机器学习的算法融合及排序后,对用户的转化有明显的帮助。
真实的商品推荐面临的问题远远比文章抽象的复杂很多。前文也调到有很多环节需要静心思考:比如,如果不能准确快速的收集数据,那后面所有模型基本不可用。