数据科学家能力素质模型
话说在遥远的 2012 年的某天,我突然感慨:作为一名数据挖掘工程师,要做好本职工作非常不易。 于是在微博上吐槽了一句,刚好被“数据挖掘和数据分析”的大 V 转发,引发了数据科学圈的广泛转发和讨论, 很多位大佬都给出了自己对于数据科学所需要能力的理解。
话题的争议性体现在一千多个转发上,放在今天必然是一篇 10 万+ 的文章。不扯别的,看看当时吐槽的是什么?

几个关键词:技术、市场、工具、战略、管理、沟通影响力…… 当然数据挖掘的内核已经随着 21 世纪最性感的数据科学家这一职业变的更加与时俱进了,然而我们依然还是有困惑。
1. 数据科学领域的工作划分
为了简化起见,后面我们统一用数据科学来定义我们讨论的问题(如果看官对数据挖掘和数据科学边界有异议的话,可以 Google 一下 KDD)。 先从这个领域从业者构成说起:
1.1. 工作类型
第一类偏重数据从无到有,数据存储和清洗,高可用平台:
- 数据开发:点击流相关、ETL 开发、爬虫工程师、数据稽核、数据血缘和治理、实时数据开发等
- 数据平台:高可用集群(离线和实时)、DMP 开发等
Hadoop 生态主要以 Java 为开发语言,所以很多平台开发工程师是从 Java 开发岗转过来的。 数据开发主要以 Python(ETL 等)和 PHP(前端的有些功能)为技能栈,从业人员主要以计算机相关专业为主。 但不同的岗位对技术和业务的侧重又有不同,比如数据开发(数仓)对如何理解业务有很高的要求, 需要大量方法论的支撑,和学习开发语言又不太一样。
这里不做展开,用一句话来表达这类型工作的意义:
数据到工具,到效率,到价值
第二类偏重描述和总结:
- 分析师:商业分析师、策略分析师、运营分析师、数据 BP 等
- BI 开发:需求分析师、利用某种工具的开发工程师(比如通过拖拽完成的 Quick BI,通过代码实现的 R Shiny 等)
这类型的工作初级、中级工程师通过“接需求”实现自身价值,SQL 和 Excel 是必备技能; 高级别的工程师需要对商业、用户、流程、模型有非常深刻的理解,且要求结论可复现,因此会要求 R 或 Python 这类环境。 当然有些分析师级别很高 Excel 也照样通天下。
分析师需要回答,资源到产出的路径;BI 开发需要呈现,数据到信息的路径。一句话总结:
数据到结论,到行动,到价值
第三类偏重推断和应用:
- 算法:算法平台、算法优化
- 数据挖掘:风控、全 CRM 流程优化(获客、交叉销售、活跃、留存等)
- 数据产品经理:面向用户的数据产品、面向内部员工的分析型 CRM 产品经理
算法类岗位主要以计算机背景的同学为主,少量统计系学生;数据挖掘岗位计算机和统计均有,但统计系学生更有优势。 为什么算法类岗位统计系的学生少,和统计系的专业设置有极大关系。 比如统计系的课程体系下,模型参数习惯追求精确解,重解释性;而计算机系侧重迭代近似解,重预测精度。
讲个笑话:大概 2010 年看到一个并行求解逻辑回归参数的方法:一份算不动,所以把数据分成十份,再把 10 个模型的参数加起来平均……batch。一句话总结这类型工种的意义:
数据到应用,到影响,到价值
以上这三大类型的数据工作,如果都做到了“到价值”,那理论上都可以称之为数据科学家。
1.2. 需求的条件
经验上说,年销售额不超过 1 亿 RMB 时,直接在生产库上跑 SQL,raw data 拿下来通过 Excel 做数据加工,基本就够用。 这时候企业面临的问题并不复杂,核心就是看个业绩结果(What),初、中级分析师可以覆盖大部分需求。
年销售额介于 1-10 亿间,企业开始关注过程中优化可能(How、Why),这时需要建制完备的平台和数仓团队,以及 BI 团队。 设想一下,没有中台的数仓,没有统一的 BI,分析师一个需求一个烟囱。长此以往,数据不一致问题会让你怀疑人生。 这个时期组织上下同域(欲)非常关键,但数据不一致各层级之间的沟通极为困难,大幅降低协同组织效率,这是企业发展的大忌。
年销售额超过 10 亿,就需要有算法、挖掘数据、数据产品的同学介入了,比如 5% 的优化就是 5000 万。 公司可以养得起这帮人了,值得规划和组建团队来做更高级、更体系的策略来支撑业务。
但是!
数据科学变为“显学”大概是 2012 年之后的事情,企业在这个方向的基因进化还不够,不是每个企业家都拥有这个能力。 一般情况下企业一号位(或 CTO)会忽视三个阶段数据团队的规划和组建,有些决策者有感觉, 但并不知道数据相关的人、财、物在何时、在什么情况下、如何推进。 当然,具备数据科学基因的企业家天然就是领先的,这是平庸和卓越的差别(有想知道卓越的企业家姓名的,可以私信我)。
2. 解决问题的数据科学家
人、财、物三个话题有点大,我们回归到人本身,企业到底需要什么样子的数据科学家?我增加了一个定语:
解决问题的数据科学家!
2.1. 如何定义的
去年,这个问题刚好在我的分析师团队的 workshop 有讨论。通过集体智慧,大家给出了以下 23 项能力。
- 统计专业知识
- 机器学习
- 编程能力
- 领域知识(营销、财务等)
- 可视化能力
- 数据预处理能力
- 报告和演讲呈现能力
- 时间规划和管理能力
- 问题界定和拆解能力
- 快速学习能力
- 系统性和结构化思维
- 价值和重要性判断能力
- 复盘和反思能力
- 沟通和表达能力
- 协作和项目管理能力
- 抗压能力
- 好奇心
- 获取有效信息能力
- 细节处理能力
- 人际关系和影响力
- 执行能力
- 决策和推动能力
- 创新能力
在进入到下个小节前,看官们可以想想是不是还缺了哪项?以及哪项你认为是最重要的?
2.2. 能力敏感性分析
显然上述 23 项能力不可能是独立的,他们之间是相互影响的。假设我们给定以下打分规则:
- 如果 A 改变一点,B 改变很大,A = 3
- A 改变很大,才能取得 B 大小差不多的改变,A = 2
- A 有了极其显著的改变,但 B 的改变还是比较弱 A = 1
- 没有影响,非常微弱,或者长时间的延迟,A = 0
经过内部讨论(人工智能,两两比较),我们得到这个矩阵(示例,从行到列):
| 统计专业能力 | 机器学习 | 编程能力 | 领域知识 | 可视化能力 | ... | |
|---|---|---|---|---|---|---|
| 统计专业能力 | 0 | 2 | 1 | 1 | 2 | ... |
| 机器学习 | 1 | 0 | 1 | 0 | 0 | ... |
| 编程能力 | 1 | 2 | 0 | 0 | 1 | ... |
| 领域知识 | 0 | 0 | 0 | 0 | 0 | ... |
| 可视化能力 | 1 | 0 | 0 | 0 | 0 | ... |
| ... | ... | ... | ... | ... | ... | ... |
我们将:
- 矩阵横向加分总和为 active total,影响其他因素程度;
- 矩阵的纵向加分总和为 passitive total,被其他因素影响的程度;
2.3. 关键能力项
我们在分析复杂系统时,关联关系实际是更为重要的信息。 尤其在穷尽系统中,如果他的 active total 巨大,这个项被解决后对其他因素的帮助也显然是巨大的。 如果 passitive total 巨大,显然这个项是被其他因素决定的,可以放在最后面解决。
将 23 个关键能力放置在平面上,并切成四个象限:
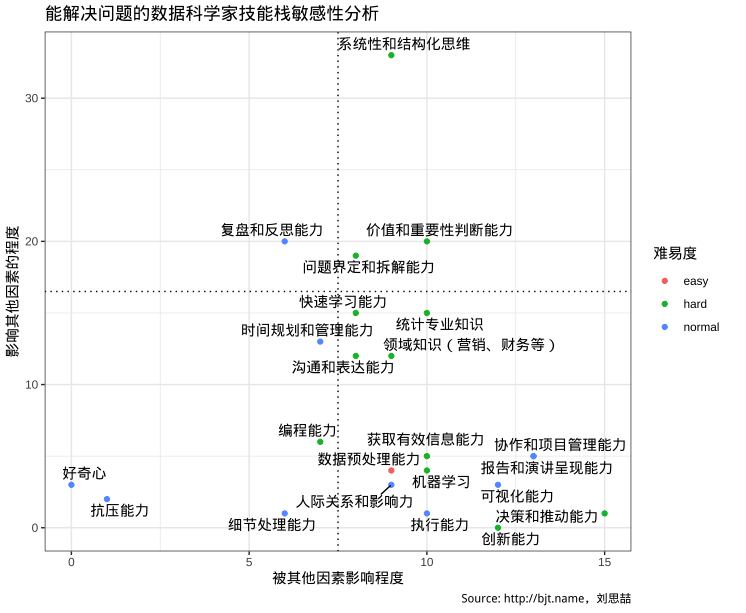
显然,应该关注最上面的两个象限:
- 右上角象限:剧烈的影响其他能力,也同时被系统中其他能力剧烈的影响。
- 左上角象限:剧烈的影响其他能力,被系统中其他能力影响较小。
关键的四项能力浮出了水面,他们是:
- 系统和结构化思维
- 价值和重要性判断能力
- 问题定义和拆解能力
- 复盘和反思能力
当然我们也很容易判断这些能力项的难易度,1-3 能力是很难获得的,需要大量经验碰撞和沉淀,故此他们存在于右上角象限。 4 可通过刻意练习习得(曾子曰:吾日三省吾身),甚至这项能力有标准方法论。
看官们可能会对结果有些诧异,拿出一项我们当时觉得有点意思的一项能力——报告和演讲呈现能力。 最开始我们认为是推动项目很关键的能力,但这张图出来后,因果非常清晰: 如果上述四项能力都很优异,报告和演讲呈现能力必然会被提高到很高的段位。
3. 方法的局限性
我们通过能力敏感分析将数据科学家的能力项做了一次全面的梳理,方法科学,言之凿凿。 但对于数据科学家的能力素质模型讨论实际上并不全面,如果大家有兴趣做一个更为全面的版本的话, 可以参考“麦克利兰能力素质模型”。
例如,我们发现的 1-3 实际上是通用素质模型中“认知族”里面的内容, 麦克利兰明确认为“认知族”是支持“影响力族”与“管理族”发挥作用的基础,已经跨越到 HR 领域,不再赘述。
本文讨论的关键能力是“解决问题的数据科学家”简化拆解模型,是一个更容易理解的版本。希望对大家思考自己的核心能力有所帮助。