SAS 一个华丽时代的结束
前几天COS论坛上还在说中科大的R镜像还没弄好,今天再看CRAN,中科大的镜像已然可以正式使用。
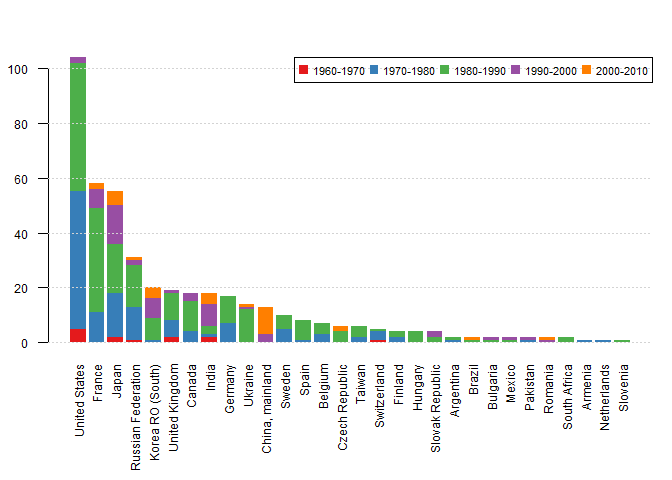
中国的 R 语言镜像近几年来变化比较大,最早是东南大学,但不知道什么原因消失了。而后国内镜像主要集中在香港的 geoexpat 和厦门大学,再后来加入了中科院的两个所(包括CTeX),到今日加入中科大镜像。个人一直觉得,人大作为中国R语言的倡导者,却一直没有提供镜像,挺遗憾的(人大文科氛围太浓烈)。
SAS
4月30日,dapangmao 在 SAS圈子更新了一篇博客——SAS,一个华丽时代的结束,具体内容见文末。不过有些奇怪的是,评论没有硝烟,不知道是因为 SAS 太封闭还是大家争累了。
MySQL
以前工作环境一般都是直接面对服务器上的Oracle、DB2,数据库安装、调试甚至数据源这些一般不用考虑。这两天项目需要,导了一些数据在本地。说来数据量也不大,1.5GB。一般的分析软件还不能直接搞定,于是乎倒腾上了MySQL。这个轻量级数据库挺有意思,注释和R是一样的(#),其前端工具
heidisql 不支持查询结果直接粘贴到word,却支持
Copy selected rows as LaTeX table,大大的逗了我一下。以前我老说
R 和 LaTeX 是天然的搭档,现看来 MySQL 也是 ^_^
SAS 一个华丽时代的结束
来源:http://www.mysas.net/sns/space.php?uid=808&do=blog&id=853
我是从 2000 年左右开始接触 SAS 的。当时还是本科生,带我的师兄要发表英文文章,杂志要求用SAS,所以需要用SAS做几个ANOVA和t-test。那时候用的SAS是存在十几张软盘上的一个dos程序,还请了高手帮我们破解,很是花了一番功夫。印象深刻的是,第一SAS的data step有一个内循环,初学者不需要基本的循环知识就可以上手,第二可以把数据直接考到程序里面,不需要像其他软件那样需要指定路径,读取硬盘上的文件。所以SAS尤其适合像大胖猫这样不是出身计算机相关领域,但是又想要做一些统计分析的业余选手。后来认真学SAS是05年以后的事情了,来到美国可以用正版的SAS,学习SAS也方便很多了。这时候的SAS是8.2版本了,该有的都有了,Proc SQL也变得很流行。再以后,变化就不大了,9.1有了hash object,9.2有了画图的SG procedures,SAS的老本行,广义线性模式,也升级到了Proc GLIMMIX。今年下半年,9.3也应该面世了。
一直在 SAS-L 潜水,觉得最近几年邮件组里人气掉的厉害,讨论的话题也一直没有什么变化,倒是跟oloolo这样的新生代大侠学到了一些新的编程风格。Oloolo大侠把一些新的算法和数据挖掘方法整合进SAS,让人耳目一新。还有经常出没SAS-L的 Liu Wensui大侠,也是华人中间的SAS高手。刘大侠的Blog也是学习SAS的好地方,他用macro封装输入-计算-输出的模式是我们规范SAS编程的好榜样,而且他很早就开始使用SAS和R的混合编程(可惜他的blog最近关门了,无缘瞻仰了)。
SAS的疲软,一部分原因是因为SAS自身的因素。SAS开发过SAS/AF和SCL,后来都失败了。一个有经验的SAS Programmer没法转变成为一个SAS Developer。 把所有的模块(Base/STAT/ETS/IML 等等)和系统(PC,UNIX,z/OS)弄过一遍就没有什么好学的了。想自己在SAS里面开发自定义模块,困难重重。另外有很大一部分原因是因为R的挑战。R最近几年的发展让人目不暇接,已经成为定量金融,生物信息学和网络分析领域的行业标准。而这三个领域恰恰是发展最快的三个领域。学习R,很快就能开发自己的package,放到CRAN上面就可以扬名立万。所以从职业生涯考虑。有能力的新人不愿意学习SAS,造成了好的SAS Programmer青黄不接。
R 的突飞猛进,一个方面因为它是开源的,学习起来很方便,不像SAS要考虑买许可证或者满世界找盗版。想用什么package,敲几个指令就行了。另外一个方面是因为原来制约R发展的内存瓶颈消失了。像Matlab和R这样的矩阵语言,里面的garbage collector不能像通用型编程语言(Java,Python等等)那样快的清空物件,所以内存很容易不够用。现在是64位时代了,买个4G以上的内存不贵。流行的分布式计算(Map/Reduce, Hadoop, Hive)和云计算也帮助解决了这个矛盾。在Amazon,Facebook,Google的数据中心里面,很容易从几千台机器里面集中几T的内存,跑跑R没有问题。大胖猫用过Amazon的EC2服务,价格很公道,也不用掏钱买另外的机器。而SAS对于比较大的数据,则只有望洋兴叹了。
SAS 每年的营业额大概是20亿美元,人数只有它1/3的Teradata的营业额也是这么多。要想提高营业额和利润,把注意力集中在电信,银行,保险,医药这些高端客户,是SAS必然的选择。SAS和Teradata都是历史悠久的老公司,SAS从60年代一个做田间统计的小软件发展到现在横跨各个领域的大家伙,的确不易;Teradata是关系型数据库的开创者,Oracle和Sun都是 这个领域的后起之秀。SAS和Teradata的确也有互补之处;也许未来两者合并,更加符合股东的利益。SAS正在开发的并行procedure就是为Teradata专门设计的。SAS的老板,Dr. Goodnight或者不愿意失去对SAS的控制权,但现实上现在的市场恐怕容不下专门的分析软件公司了。统计软件界另一个和Goodnight齐名的传奇人物,Dr. Nie,果断卖掉SPSS是一个正确的选择,借助IBM的国际影响力,SPSS在世界其他国家卖的还不错。将近七十岁的老聂看到R的潜力,重新创业,现在他的Revolution R看上去发展势头不错。如果他还呆在SPSS,现在的情况就很难说了。
由于 SAS 是行读入的,所以特别适合整数据,我经常没事到各个论坛找些题换几种做法做做,其实跟电脑游戏一样好玩。感谢SAS帮我学会了统计和编程,伴我度过异国他乡的漫漫长夜。虽然属于SAS的华丽时代不会再有,但我仍会纪念开创那个时代的伟大的SAS程序员。Old SAS programmers never die, they just fade away.