地震和核电站的世界范围分布
2011年3月11日日本福岛9.0级大地震以后,紧接着是海啸,跟着福岛核电厂接连发生爆炸。如果开始还可以说是电影《日本沉没》的剧情的话,那核电站爆炸的后果,可就有点像《生化危机》前奏的味道了。
民众对于核辐射污染的担心要远超过地震和海啸。就拿前几天国内发生的碘盐抢购事件来说,虽然主要原因是民众对政府的不信任(对比日本灾民的有序和平静),但很大的恐慌来自于人们对核辐射的危害的恐惧。
从各国对核武器的态度以及实际行动上看,核武器和核污染基本不沾边。一旦发生了核污染,那必定是和核能电站有密切关系。而这几年,我国政府既要保证高速经济增长所需要的电力能源,又要尽力控制二氧化碳排放,那大力发展核能便是上上之选了。本来这等国家大事和我等小民也没什么关系,不过上次回老家,偶然听说河北要建四座核电站,其中一座就在离我老家不足4公里的位置。
枕头边上放一个随时爆炸的定时炸弹,这事不关心也不成了。随手翻了翻网上的资料,发现前期的选址和研究审批已然结束。(我等一厢情愿的认为,这种事情是应该公投的,至少要听证一下吧。从现在我周围人态度上看,肯定不可能通过。如果通过了,我们那儿将继重污染企业首钢搬迁后,又一次为伟大祖国首都——北京做的巨大贡献)。
核能是潘多拉盒子,这次日本的核泄漏给大陆敲响了警钟,有评论说,两会上刚刚获得通过的“十二五”规划中的核能规划后续也可能会有很大变动。和普通人一样,我也怕核辐射,更怕核辐射毁掉家园。核能电站的建设需要有极专业的考证和后续严谨的政府管理,如果我是日本人,我相信这两点。但不幸的是,我是中国(大陆)人,这两条我都不信任。一个最基本的常识上——核能电站不应该建设在地震带上。
最近花了一些时间,零零散散地收集了一些数据,附一些分析。还是那句话,我等小民虽说不能决定此等国家大事,但心里明白明白也是有必要的。首先是世界范围,各国拥有核电站的数量:
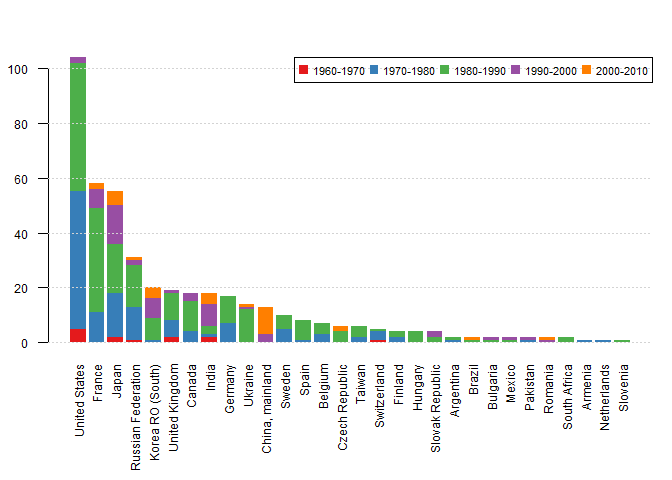
可以看到,世界范围核电排名前四的国家分别是美国、法国、日本,俄罗斯联邦,我国排名第十,和发达国家确实有段距离;这排名前四的几个国家的核电基本都是在1970-1990时间段建设,而近十年发展速度明显降了下来。但反观中国大陆,大部分核能电站都是在2000-2010年期间修建,并且在规划中的核电站(反应堆)更多。
而从日本核电站事故上看,核能电站修建在地震多发地带是非常不明智的,即便是有多重的防护措施。我们关注一下,地震多发地带和核电站分布重合的程度。下图标记了1973年至2010年,世界范围内的1级(包含)以上地震分布(红色为实际的地震发生地点,蓝色为当年发生地震的密度),以及每年各国存量核电站(绿色点标记)的情况:
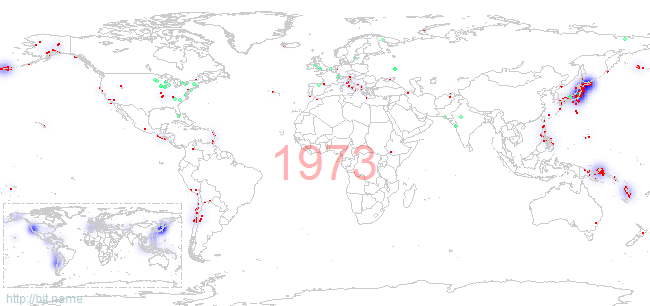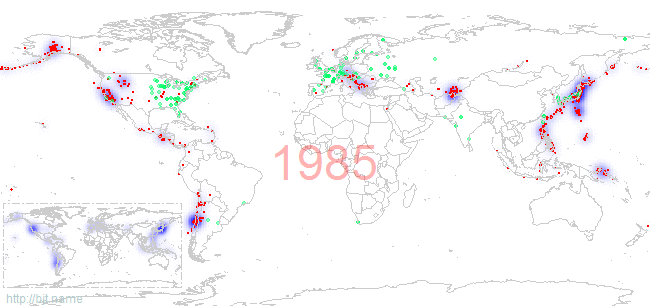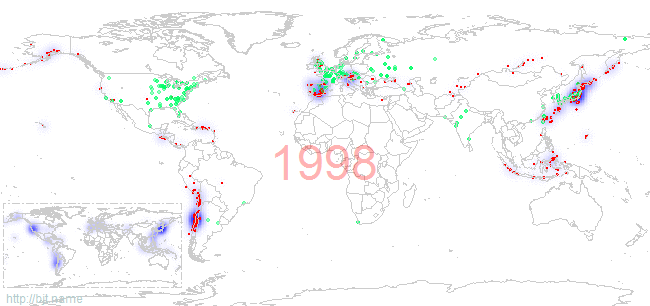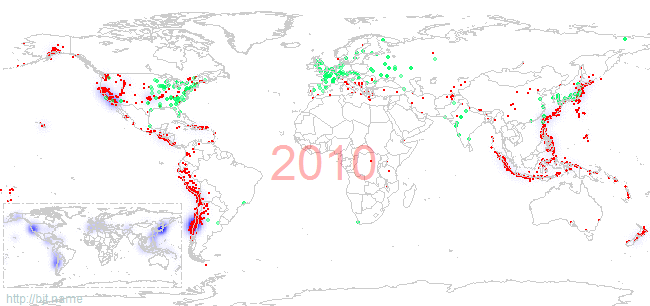
左下角的小图是1973年至今所有世界一级以上地震发生的高概率区域,从这个小图上看,日本、美国西海岸、南美洲西海岸是高发地震区域。最近发生在这三个区域的大型破坏地震有:智利2010年8.8级、日本2011年9.0级、美国加利福尼亚州2003年6.5级(不过加州的这次好像还不够,有报道说可能还会发生更大级别的地震)。
美国的大部分核电站都修建在东部地区,而在地震高发的西部地区,核能反应堆的数量明显很少,最大程度的降低了地震对核能电站的影响;而日本就比较郁闷了,整个国家都处在地震高发区上,核电站修的又很密集,出现3月11日的事件有其必然性。
那对于我国呢,不言自明:修在唐山这种时不时就震一下的地方是绝对不应该的,修的话向内陆靠一靠,离地震发生高概率区域远一些!
最后在扯一句,大地震似乎总和核爆有关系,包括中国汶川、日本福岛,随便搜一搜可以罗列关于很多核试验的传闻。也许渺小的人类看到的毁灭性的灾难都是一个样子吧。