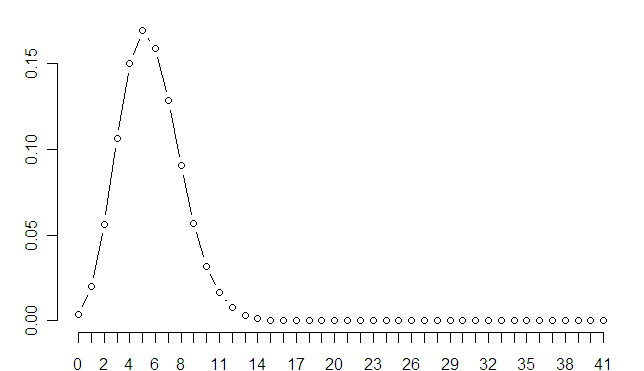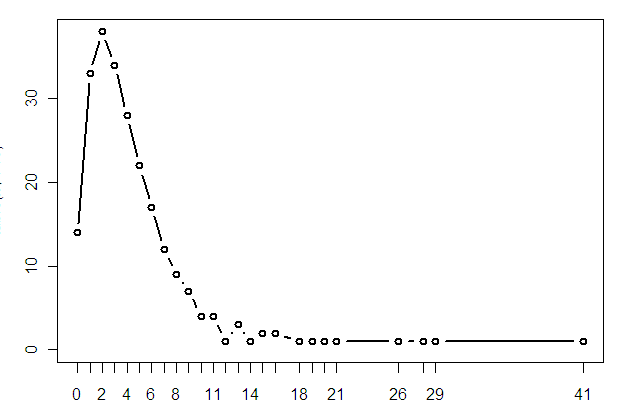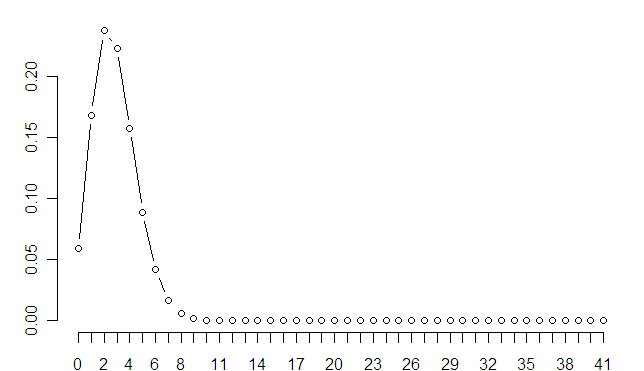数量庞大的包,复杂的网络
R 各个镜像中的 Contributed Packages 越来越多,截至今日,已经达到1950个,单单拉动鼠标把所有的 包名 从 A 到 Z 过一遍也得 10 几秒。随便考你一道:最后一个 R 包是啥?
zoo?
呵呵,我的印象里一直是它,仔细瞧了瞧发现是个叫 zyp 的包。
又一次领略了 R 强大的扩展能力撒?这个特点给我们带来了一些烦恼,因为人类的大脑能够理解的概念是有限的,对于没有任何关联的概念,我们的识别能力一般不超过 7,而且 R 的涵盖范围实在太广。从我们的有限性(7个概念)和 R 的无限性这一角度讲,逐一认识这些包几乎是不可能的!不过还好,至少我们可以可以参考 CRAN 上的 Task Views,大致了解 R 包的使用方向。
我们换个思路,不是从 R 的使用方向上,而是从 R 包的依赖关系上?
这些 R 包并不是相互独立的。比如说,MASS 包依赖于 R (>= 2.5.0), grDevices, graphics, stats, utils 这些基础包;而又会有包依赖于 MASS 包,比如 yihui 的 animation ,当然还有可能有包依赖于 animation ……
遍历所有的包,我们就看到了一个网络,一个 R 包的网络。
为了简化起见,这里忽略了同其他包没有关系的包(当然并不是完全没有关系,所有的包都和 R 或 R 的基础包有关,如果这样计量的话,会导致所有的包都会指向 R)。
首先截取了这个庞大网络的一部分:

从上图我们可以看到,标记点为215、271的两个包是我们研究的包网络中的两个关键点,这两个包分别是lattice、mvtnorm。
关于这两个包:-
lattice:网格绘图的基础包。很多包基于它扩展并不惊讶吧;
-
mvtnorm:多元正态分布和t分布的概率密度函数、累计分布函数、分位数函数、分布随机数。多元分布的基础。
从 271(mvtnorm)向左上,又会有一个小的聚集。那个小的聚集中心(110),是 fBasics 包,如果各位对金融领域关注的话,应该知道它在其中的地位吧。
当然,由于抽取的是一个子网络,很多的连接都被生硬地隔断,因此出现了大量的孤立点。
如果我们把 CRAN 上的1950个包都放到我们的网络中会是这样:

- 第一张图的 包 id 换成 包名称 会导致 演示的视觉效果很差,网页又不支持 pdf 直接显示,只好把带包名的图放这(pdf)。
- 带包名的 ,1950 个包的全图就算了吧,单绘图就得 2 分钟,更别提调整参数了 ……