明朝那些事儿的那些事儿
前段时间同事推荐《明朝那些事儿》,正好上班路上无聊,于是下载了电子版通读了一下。果然,作为汉族最后一个王朝——大明的历史非常有意思,各种不可思议,各种匪夷所思。个人觉得作者的确有功底,但精彩还是来源于辉煌壮丽的明史。
职业习惯,顺手把《明朝那些事儿》中所有的人物关系绘制一下,正好作为明史的温习:
前段时间同事推荐《明朝那些事儿》,正好上班路上无聊,于是下载了电子版通读了一下。果然,作为汉族最后一个王朝——大明的历史非常有意思,各种不可思议,各种匪夷所思。个人觉得作者的确有功底,但精彩还是来源于辉煌壮丽的明史。
职业习惯,顺手把《明朝那些事儿》中所有的人物关系绘制一下,正好作为明史的温习:
R 2.14.0 版本以后,parallel 包被作为核心包引入 R,这个包主要建立在 multicore 和 snow 包的工作基础之上,包含了这两个包大部分功能函数,以及集成了随机数发生器。
实际上对于R来说,并行化可以在不同的层级上实现:比如,在最底层,现在的多核CPU可以实现一些基础的数值运算(比如整数和浮点算数); 高级一点的,一些扩展 BLAS 包使用多线程并行处理向量和矩阵的操作,甚至有些R扩展包,通过调用 OpenMP(注释1)或 pthreads 来使用C 级别的多线程方式。
第13期KDnuggets 关于数据挖掘软件的调查结果新鲜出炉,调查了对于过去的 12 个月里实际的项目过程中使用了哪些数据挖掘(分析)软件?不出所料,底层语言使用频率最高的是依旧是 R 语言、SQL、Java和 Python。而从软件工具角度上看,R、Excel和RapidMiner则名列三甲(去年R排名第二),具体排名如下图:
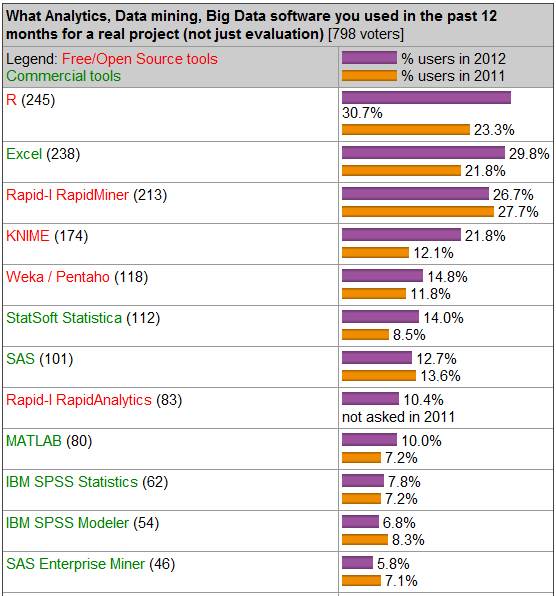
可以看到,排名靠前的以开源软件为主,商业软件则相对靠后。造成这种现象的原因很多,其中一条比较重要的因素就是当今社会复杂的数据环境,必须有更加灵活的软件做支持,灵活则是生命力。这个角度上看,闭源的商业软件依旧停留在上个世纪 70 年代 batch 的方式,曾经积攒的优势越来越不明显。
对于同 R 语言同级别的 SAS 而言,在这个调查下其使用流行度进一步萎缩。甚至有人估计,2015 年将是 SPSS 和 SAS 历史的终点。
其实我不太想看到这一天~~
在我还没回过神的时候,今年的 R 语言会议北京场己经结束,伴随着早上迷糊的送走李舰,意味着这次相聚终于曲终人散。本来我不是伤感的人,但今天看到邱怡轩师弟的一句微博:
感谢几位引路人。@谢益辉 @刘思喆 @雁起平沙 @thinkfan
这个中滋味……
这些年,和周围的朋友们一起成长,一起为了一个目标努力。大家同分享,同分担,俨然一个大家庭一样,想到马上这些优秀的师弟、师妹们都会远赴大洋彼岸,真的很失落。
R会议结束后,大家又一起和熊师妹过生日party,遥想去年还有江堂,现已身居美帝。紧接着就是轩、熊和岚,明年的这时候再聚又会少了很多。也许相聚的次数越来越少,正如堰平所说,有的人一转身就是一辈子。
最后来张照片——非常荣幸能够受到伯克利统计系郁彬教授的教诲。郁老师同大家分别时,饱含深情的一席话:
You are the future of statistics!
与致力于统计事业的各位共勉!

前段时间在老家给小舅子补习高中数学,其中有一道数列的求解,题目是这样的:
求 a_n 的通项表达。
解题思路是先构建等比数列 b_n,再将等比数列 b_n 变形回 a_n ,求得通项。 这道题实际就是费波那西数列的初等代数求法。费波那西数列在科学、自然界等很多领域都有表现, 比如我们常说的黄金分割比(1.618),即是两个相邻费波那西数的比值
f(n + 1)/f(n) = (1 + sqrt(5))/2
还有美丽的向日葵的花盘中果实:
