数据科学的关键事件
十月份在公司的技术中心分享了《数据思维、技术到商业价值》,从数据科学的重要基石之一统计学开讲,帮大家串了一下数据科学到底是什么东西。其中有一页幻灯片,讲到我心目中数据科学 milestone 的时间轴,这里分享给大家,以及怎么使用 R 包绘制。啥也不说,先看图:
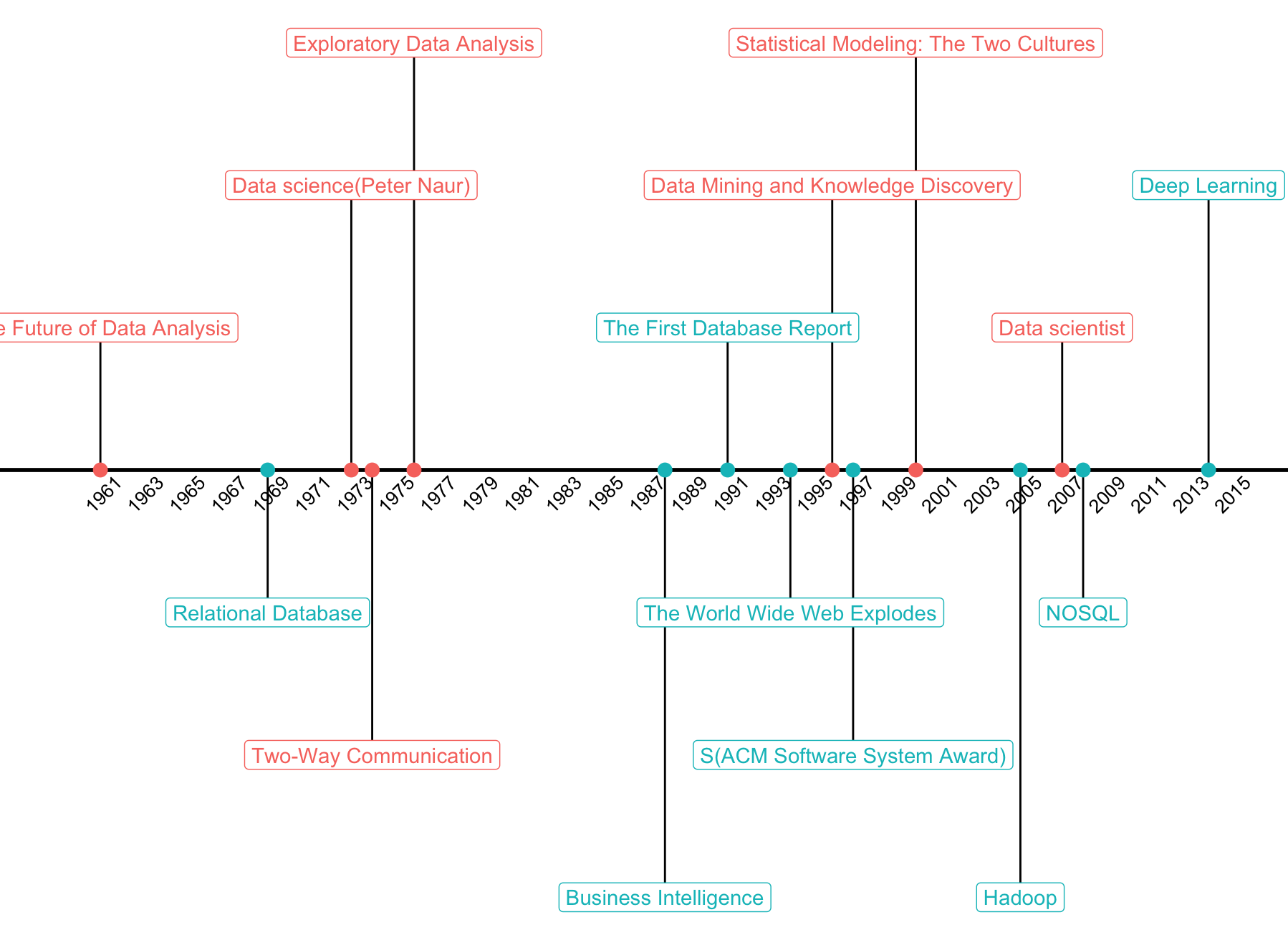
十月份在公司的技术中心分享了《数据思维、技术到商业价值》,从数据科学的重要基石之一统计学开讲,帮大家串了一下数据科学到底是什么东西。其中有一页幻灯片,讲到我心目中数据科学 milestone 的时间轴,这里分享给大家,以及怎么使用 R 包绘制。啥也不说,先看图:
Bayesian Personalized Ranking 是基于隐式反馈数据的非常通用的个性化模型,一般实现使用的是 matrix factorization 机制,利用随机梯度下降来求解。
假设用来表达训练集的三元组为
它有以下几点优势:
本片文章直接拷贝于部门 wiki,作者还有 renwanfeng、duyalei
写轮眼是谢益辉开发的,利用 markdown 语法完成的 slides 的工具, 排版非常考究,书写速度极快。非常适合工程师序列的工作人员。
不过因为 GFW 的存在,sharingan 调用的 js 和 font 不能加载,会导致 slides 不能被顺利渲染。 这里提供一些常用参数设置,通过本地编译,sharingan 能够提供 self-contained 文件,不依赖于网络环境。
六月的最后一周,在厦门大学统计系做了一份小学期课程的分享。午餐期间,胡帆同学整理并提问了一些问题。感谢 WiseRClub 的文字整理。
胡帆:
您是正儿八经的统计学专业出身,但是现在统计学出身的人大部分都在做机器学习,请问您认为统计学和机器学习的联系和区别是什么?
刘思喆:
其实没有什么大的区别,简单的说:计算机系和统计系各自重新把数据科学发明了一遍。计算机的人做很多东西,跟统计系做的很多东西其实都是一样的,只是在概念上不一样。经常地,统计系的学生和计算机系的学生在聊天的时候发现,我们说的是一个东西吗?后来发现,就是一个东西! 举个例子:统计系的学生在讲到回归的一些变种的时候会讲到 Lasso,而计算机系的学生是从来不会讲 Lasso 这个概念的,他们叫 L1 正则;而计算机系学生所说的 L2 正则,就是统计学中的 Ridge regression(岭回归)。其实他们的本质都是在解决数据科学中的一些问题,计算机的人走自己的一条路,而统计的人走的是另一个方向,但实际上我们所解决的问题都是一样的,这个现象最近几年愈演愈烈。大量统计压箱底的好物件,被计算机背景的人不停的翻出。事实上每个系或者每个专业背景的人其实都有自己的优势,我觉得最终会殊途同归。 所以,我们经常说一句话:“一个好的程序员必须是半个好的分析师,一个好的分析师必须半个好的程序员”。这句话虽然粗糙,但我觉得比较好的描述这样一个观点:统计系的学生或者有统计专业背景的人,应该擅长自己统计那块,但是编程这块也要至少能及格;而计算机那边的人呢,如果只做软件工程,那是不够的,他要能够掌握基本的统计思想。
思路可借鉴,但内容已经过时,请忽视。可转向 https://github.com/rexyai/RestRserve
前文说到使用 opencpu 来搭建 http 服务,opencpu 可以很快速的通过构建 R 包的方式来搭建 http 服务, 很快捷,而且支持各种响应机制。但我们在搭建线上服务时,经常有需求将请求响应的时间控制在 100ms 以内,opencpu 的框架就存在问题了。 这里再介绍 R 的另外一个包:fiery,部署更加方便且响应优势更加明显(一般 30ms 以内)。
首先假设我们面对的场景是垃圾邮件预测,已经根据离线数据构建了预测模型:
1 | library(xgboost) |
假定我们线上预测流程是这样: