数据分析师的生存手记
本篇关键内容(阅读需要约 15 分钟):
- 分析师的职责范围
- 重定义:数据科学合作伙伴
- 数据需求的标准流程
- 工欲善其事,必先利其器 - tapd
为什么写这篇文章?起因是分析师团队的 leader 离职了,作为大老板,我只能选择暂代管理一段时间。在帮团队成员梳理工作内容的过程,我抽象了其中一些关键的要素,以及需要澄清的认知误区。这些总结我不想仅仅封闭在自己的团队内部,还希望能帮到正在职业生涯迷茫的分析师们。
本篇关键内容(阅读需要约 15 分钟):
为什么写这篇文章?起因是分析师团队的 leader 离职了,作为大老板,我只能选择暂代管理一段时间。在帮团队成员梳理工作内容的过程,我抽象了其中一些关键的要素,以及需要澄清的认知误区。这些总结我不想仅仅封闭在自己的团队内部,还希望能帮到正在职业生涯迷茫的分析师们。
各位看官在平时用 R 处理网页的过程中,一定会被各种乱码、转码所困扰,这里做一些小型的总结,会涉及到:
逐个解释如何处理:
Encode 和 Decode 处理最为简单,因为在 R 中自带的 utils
就存在方法,具体函数是 URLencode 和
URLdecode。
国庆期间闲逛知乎,恰巧碰到一则问题 2019年你的书单有什么书?,这个问题有
988 个回答,18326 个关注者,284 万的浏览量
接近 1000 个回答,全部翻完且不说时间会爆炸,脑子里能不能记住这些信息更是问题。如果能抓取每个回答列出来的书名,汇总以后便是这 988 个回答者的书目投票。方法虽说暴力,但也算是变相了解大家在 2019 年的阅读倾向。工具呢?当然是我擅长使用的 R 了,哈哈!
闲话不多说,直接给出结果(大于 10 位回答者提及的书目):
拜川普总统所赐,今年的国庆节国人过的非常振奋。
此生无悔入华夏,来世愿在种花家
这句话说出了很多人的心声。
情怀归情怀,我们从建国以来到底 成长的怎样
呢?闲话不说,直接上图,数据来源这里。
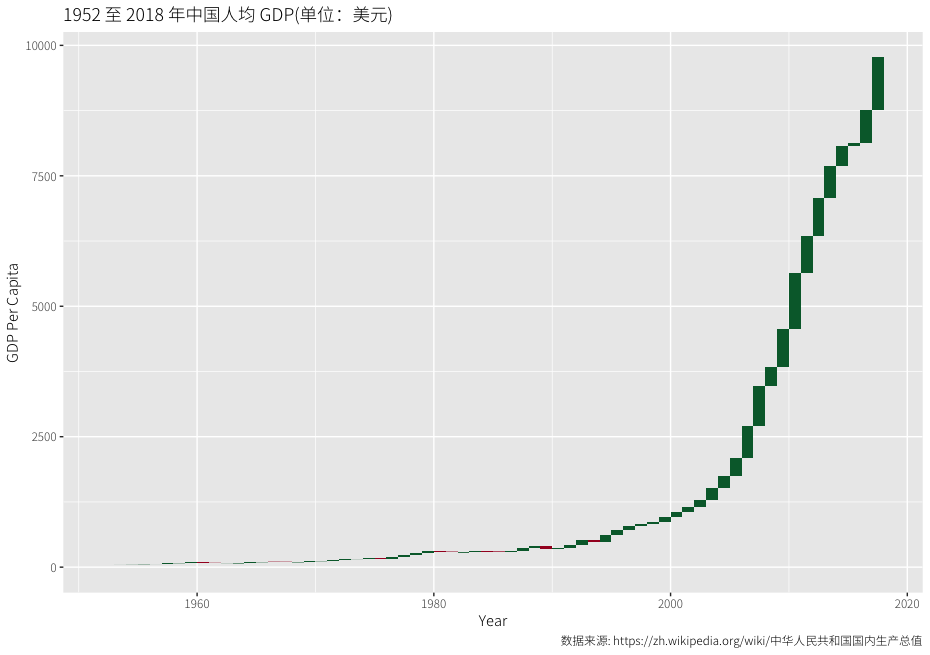
改革开放 40 年我们取得了非常傲人的经济成就,作为 80 后亲历者,图形化的结果还是震撼了我。从 04 年附近,人均 GDP 的增幅突然爆发出了一个向上的拐点,全球第二大经济体,这么巨大的体量居然还能做到如此,真心不容易!我们大部分普通老百姓即便是什么也没有做,生活水平也在跟着水涨船高,感谢我的政府!
随着我们注册的网站和 App 越来越多,有一个问题一直困扰着我:
我的密码真心不够用!
经常几个可能密码重复的尝试,时不时网站就报超过尝试次数。以及还有一个更为可怕的风险:如果所有的网站如果使用同样的密码,任意一个网站只要发生安全泄露(这几年发生次数不少),那基本你在其他网站就属于裸奔了,其他人可以利用你的统一密码作出一系列你不能想象的行为。
1Password 给我了一些启发,它可以保证你每个网站的密码都不同。这款软件安全性怎样,收费多少先不提,我们简单思考一下这个软件的原理貌似是容易实现的,基本要素和逻辑猜测有以下要点:
这样做的最大好处是,我只需要记住 2 的种子,即便暴露了 4 的规则,也不担心密码会被反向破译。