时空数据科学概念和技术
叶文洁是第一个通过太阳向宇宙发出了信号的地球人,从而暴露了地球在茫茫宇宙中的坐标,成为了三体人进攻和侵略地球的开始。
《三体》小说贡献了太多的经典桥段,“不要回答,不要回答,不要回答”的黑暗丛林法则也让人印象深刻。不过,我们较个真,从科学的角度聊聊需要具备怎样的条件,才能把地球的坐标发出去。为了类比,我们小处着眼,先理解一下在地球上的坐标是咋出来的?
1. 坐标系
世界大地测量系统(World Geodetic System, WGS)是一种用于地图学、大地测量学和导航(包括全球定位系统)的大地测量系统标准。WGS 包含一套地球的标准经纬坐标系、一个用于计算原始海拔数据的参考椭球体,和一套用以定义海平面高度的引力等势面数据。
地球的形状不是完美的球形。因此,当我们试图近似地球的形状时,需要一个更好的模型。这个模型就是 WGS84 坐标系:它的坐标中心点为地球质心,采用一个十分近似于地球自然形状的参考椭球体,作为描述和推算地面点位置和相互关系的基准面。
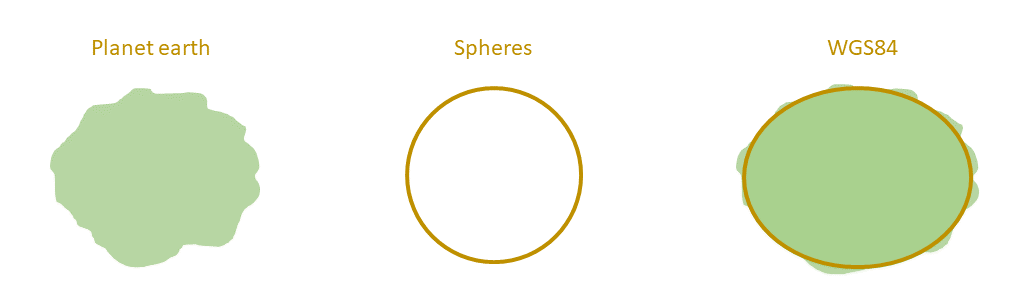
有了这个椭球体,地球上任意一个点就可以在这个体系中有唯一投影。这个投影一般使用经度和纬度两个数据,表达该点的位置(也可以有高度)。
WGS84 是世界上第一个统一的地心坐标系(最后修订于 2004 年),因此也被称为大地坐标系、原始坐标系。不同的地区地理信息差别较大(海拔、地表趋势等),为了更精确的表达信息,各地使用的参考椭球体(或参数)不同。欧洲石油调查组织(EPSG)的成员在 1985 年发起了一个介于1024 和 32767 之间的 EPSG 注册表,这个注册表包含了大地基准面、空间参考系统、地球椭球体、坐标变换和相关测量单位等信息。
EPSP 的英文全称是 European Petroleum Survey Group,中文名称为欧洲石油调查组织。这个组织成立于 1986 年,2005 年并入IOGP(International Association of Oil & Gas Producers),中文名称为国际油气生产者协会。选择不同的座标系对于油气勘探的成本至关重要,所以有不同的座标系,这也是为什么这个注册码是从 EPSP 发起的。
对于中国来讲,以地球的几何球心为中心的中国地图注册码就是 EPSG:4479,以地球的椭球焦点为中心就是 EPSG:4480。
由美国提供服务的全球定位系统(GPS)使用的就是 WGS84 参考系(EPSG 注册代码为 4326)。国家测绘局为了安全考虑(里面的八卦很多,看官感兴趣可自行搜索),要求互联网企业在国内不允许直接使用 WGS84 坐标下的地理数据,于是开发了加密的 GCJ-02(国家测绘局 02 年的简写)。这套体系是在 WGS84 之上做了变换,大约有几百米的偏移量,从视觉上会感觉好像到了火星,所以民间也称 GCJ-02 为火星坐标系。百度地图又在 GCJ-02 上多增加了一次变换,用于自己的地图商业解决方案,标识为 BD-09(百度 09 年的简写)。
下面列出了各个主流地图厂商在各地使用的坐标系(请注意,把百度的坐标放到高德地图中,位置会发生错乱,坐标和坐标系需要统一):
| 地图 | 大陆/港/澳 | 台湾省 | 海外 |
|---|---|---|---|
| 高德 | GCJ-02 | WGS84 | WGS84 |
| GCJ-02 | WGS84 | WGS84 | |
| 百度 | BD-09 / GCJ-02 | BD-09 / GCJ-02 | WGS84 |
2. GPS 的工作原理
GPS 是美国第二代卫星导航系统。它是在子午仪卫星导航系统的基础上发展起来的。GPS 卫星在大约 20200公里的高度的中地球轨道(MEO)飞行,每颗卫星每天绕地球两圈。GPS 卫星排列成围绕地球的六个等间距轨道平面,每个平面包含由基线卫星占据的四个 slots,这种 24 slots 的卫星布局,确保用户可以从地球上的几乎任何一点查看至少四颗卫星(2011 年 6 月美国空军又在这 24 个卫星基础上新增了 3 个扩展卫星,以提高卫星可用性和空间整体信号性能的稳健性)。
如何计算观测点的坐标呢?
GPS 卫星轨道参数已知,且会不停地发送报文信息,所以我们知道卫星的位置(xyz)。报文到达接收器有时间差,乘以光速,就是观测点到达卫星的距离 d。从空间几何上看,可以得到以 GPS 卫星为中心,半径为 d 的圆球。显然有只要存在三个圆球,它们的交汇点即是观测点的位置。
当然这里面有两个细节:
- 光速实在太快了,时间稍稍差一点,观测点到达卫星的距离就错了。因此每颗卫星都需要有原子钟来精确表达时间(铯钟,我国的最新记录是 6000 万年不差一秒,显然石英钟精度不够)。
- 观测点的接收端还需要修正本地时间的误差,因此还需要一颗额外卫星(额外的一条数据)。
还有种说法是,默认每颗卫星的时钟都是准的,增加一条额外数据,通过最小二乘的方法(4 条数据求 3 个参数)求解接收点的位置。
在求解了接收点的空间位置(xyz)之后,显然很容易投影到 WGS84 这个椭球上,那么我们常见的经度和纬度就得到了,即接收点的位置。
另,我国的北斗卫星比 GPS 还要高级,GPS 只能单向发信息到终端,北斗还可以在终端发送短报文给卫星,再回传基站(求救中心)。
3. 位置数据的格式
Simple Features 是一组标准,用于指定地理要素的通用存储和访问模型,该模型主要由地理信息系统使用的二维几何(点、线、面、多点、多线等)组成。它由开放地理空间联盟(OGC)和国际标准化组织(ISO)正式确定。
该套标准约定的常见数据格式是 WKT(Well-known text),点、线、面等几种类型(GEOs 中称为 Geometry)数据的示例如下:
| 类型 | WKT |
|---|---|
| Point | POINT(10 10) |
| LineString | LINESTRING(10 10, 20 30) |
| Polygon | POLYGON(10 10, 15 16, 30 32) |
| MultiPoint | MULTIPOINT ((10 40), (20 20), (30 10)) |
| MultiLineString | MULTILINESTRING ((10 10, 20 20, 10 40), (40 40, 30 30, 40 20, 30 10)) |
| MultiPolygon | MULTIPOLYGON (((40 40, 20 45, 45 30)), ((20 35, 45 20, 20 35))) |
在 R 中使用 sf 包来支持这类型数据,我们看一个经纬度数值转化为 WGS84 大地坐标系的例子:
1 | library(sf) |
这样我们就将这两个位置对应位置信息以及不同的描述信息组合在了一起。
还有一种格式是 GeoJSON,基于 JSON 的 Feature 输出格式,它便于被 JavaScript 等脚本语言处理,OpenLayers 等地理库便是采用 GeoJSON 格式。
4. Uber 的全球 H3 体系
H3 是 Uber 开源的一个地理空间索引系统,它可以将地球表面分成一系列六边形的网格,并对每个六边形进行编码,从而实现对地球表面的高效索引和查询。H3 的设计目标是提供一种高效、可扩展、灵活的地理空间索引方案。
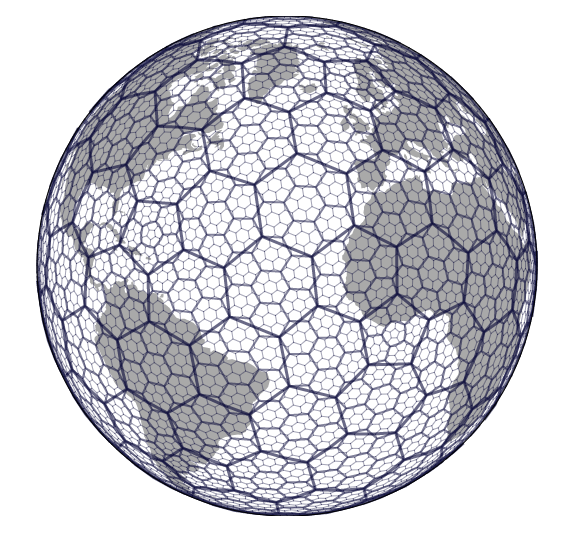
H3 的六边形网格是根据一定的分辨率级别进行划分的,分辨率级别越高,网格越小,精度越高。H3 支持 16 个不同的分辨率级别,从全球范围到具体的街区和建筑物等级别都可以进行索引。每个六边形都有一个唯一的 H3 编码,可以用于快速查找和比较不同的地理位置。每个六边形大致覆盖 7 个子六边形,也就是说子六边形面积大约是父六边形的 1/7。以下的示例是根据前文中提供的两个点返回的 resolution 为 8、9、15 六边形区块的索引。
1 | library(h3jsr) |
H3 广泛应用于各种地理信息系统,如共享经济、交通运输、城市规划等领域。例如,在 Uber 的出行服务中,利用 H3 快速计算乘客和司机之间的距离和路线,辅以车乘匹配算法,提高乘客出行效率。以下代码的意思是将前文提到的点转化为 resolution 为 8 和 9 的 H3 cell,并找到 9 级 H3 cell 对应的最短路径。
1 | library(ggplot2) |
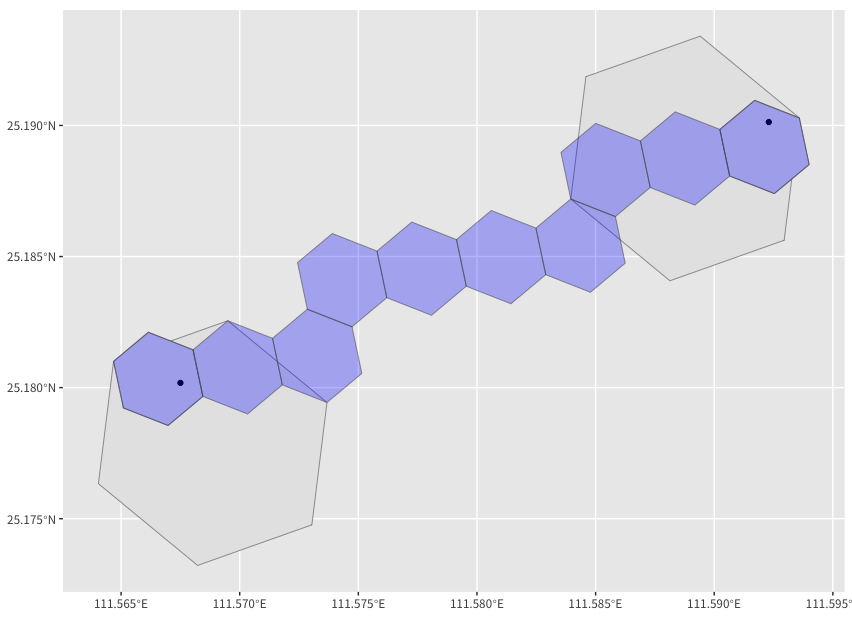
H3 最大的好处是将全球所有的位置以不重不漏的方式进行了重组,极大的方便了我们对于空间中点(比如人、车、事件等)的后续分析。
5. 空间拓扑关系
已知两个几何对象 A,B,看他们之间的关系:比如一个点是不是在一个面里,面和另一个面是不是重叠?……这些说的就是空间拓扑关系,常用的拓扑关系有这些:
- Intersects
- Disjoint
- Contains
- Within
- Equal
- Overlap
- Touch
- Cross
客官如果有兴趣可以参考“九交模型(DE-9IM)”,这套拓扑模型有更加科学和严格的定义。
在实际项目中 Contains 这个关系用的最多,拿一个例子说明:有 2 个车站(定义为:前文提到的 df 是站点的中心,半径为 450 米的圆),判断每个车站内有几辆车。
1 | set.seed(1) |
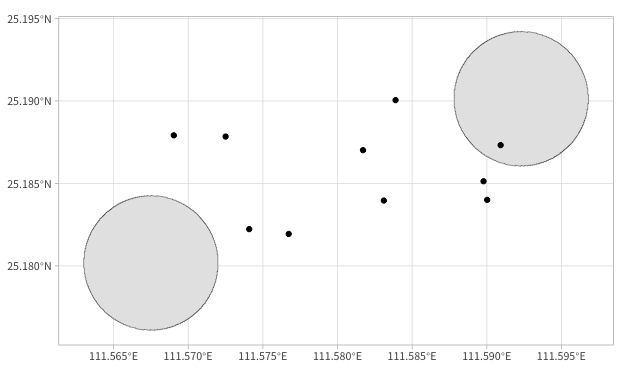
这里有一个细节,我们做空间拓扑的包含判断,数据量少的话性能还 OK,但数据量一旦上来,会出现巨大的笛卡尔积,性能会出现指数级下降。这个问题在 sf 包中已经被考虑,通过构建空间索引,计算耗时基本是线性的,细节可以参考这里。另外,其他时空工具也同样考虑了这个性能问题,这也是为什么空间统计是独一份存在。
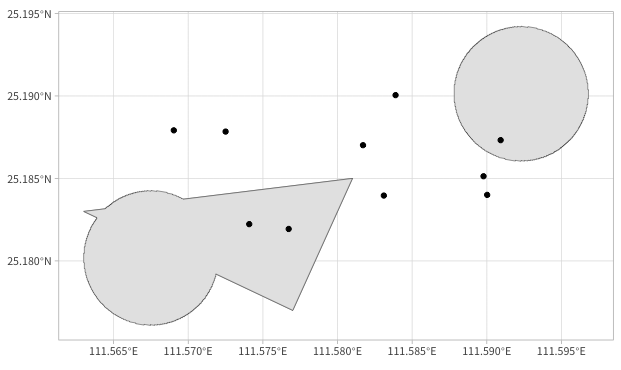
再来个例子:因为业务考虑,其中一个车站要更大(具体是和一个三角形合并),再判断车在不在这两个车站。
1 | ## 假如我们要增加一个三角形 polygon |
6. 平面可视化
前面的小例子都是在地理坐标系(Geographic coordinate system)下做的说明。如果我们需要和实际地图做联动的话,就需要从地理坐标系的三维投影到电脑屏幕的二维上,这时需要使用投影坐标系(Projected coordinate systems),常用的是墨卡托投影(Mercator)。需要注意的是,墨卡托投影纬度越高,放大效应越厉害。下图是墨卡托投影下每个国家的大小和实际大小的差别:
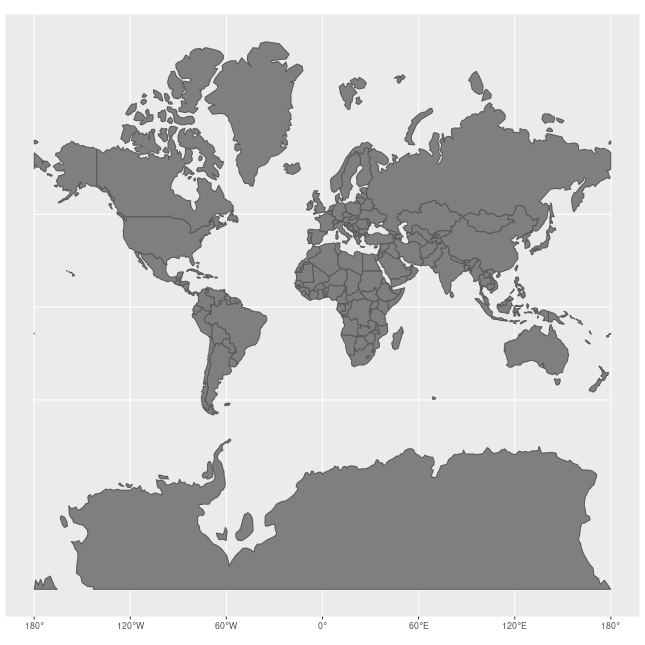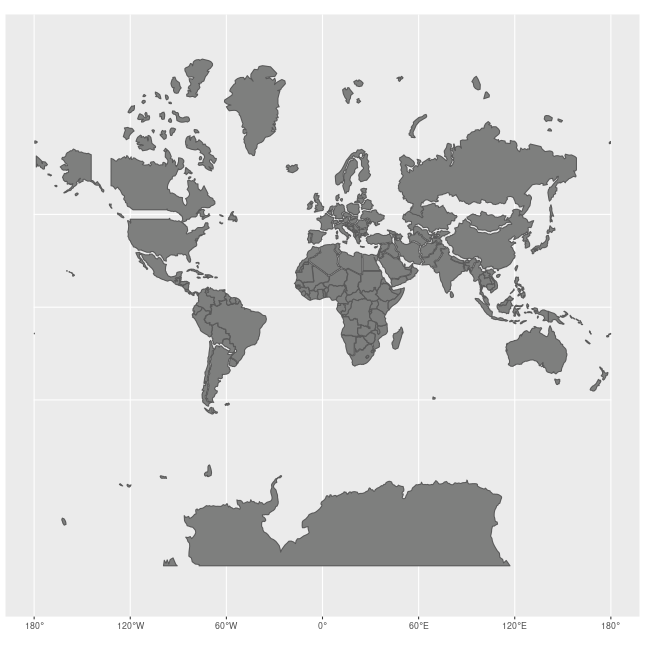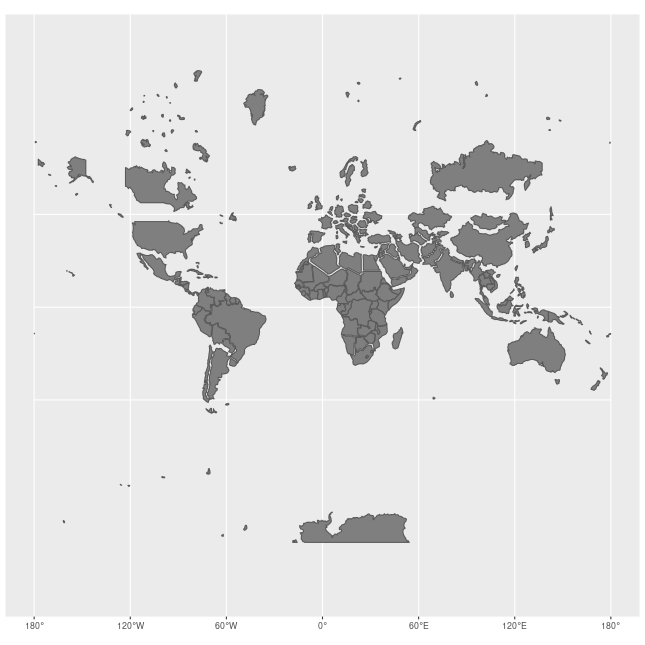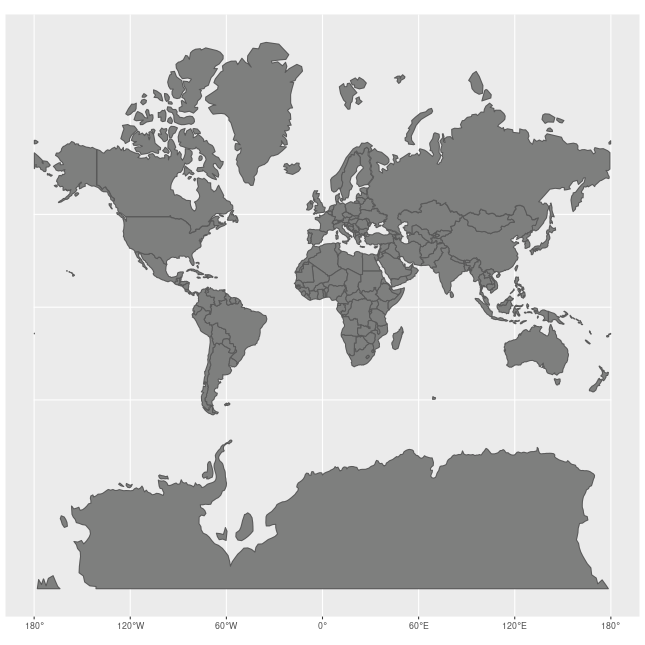
墨卡托投影的线型比例尺在图中任意一点周围都保持不变,从而可以保持大陆轮廓投影后的角度和形状不变,非常适合做二维平面可视化。墨卡托投影对应的 EPSG 注册码为 3857。目前主要是各大互联网地图公司以它为基准,例如 Google 地图,Microsoft 地图。
假设我们希望绘制一个点,这个点是全国最贵农田的坐标(lng=116.331415, lat=39.965217,猜猜是哪)。使用百度坐标在 leaflet 中做展示,需要配置好 EPSG 相关的参数和百度自己的地图瓦片,代码见下:
1 | library(leaflet) |
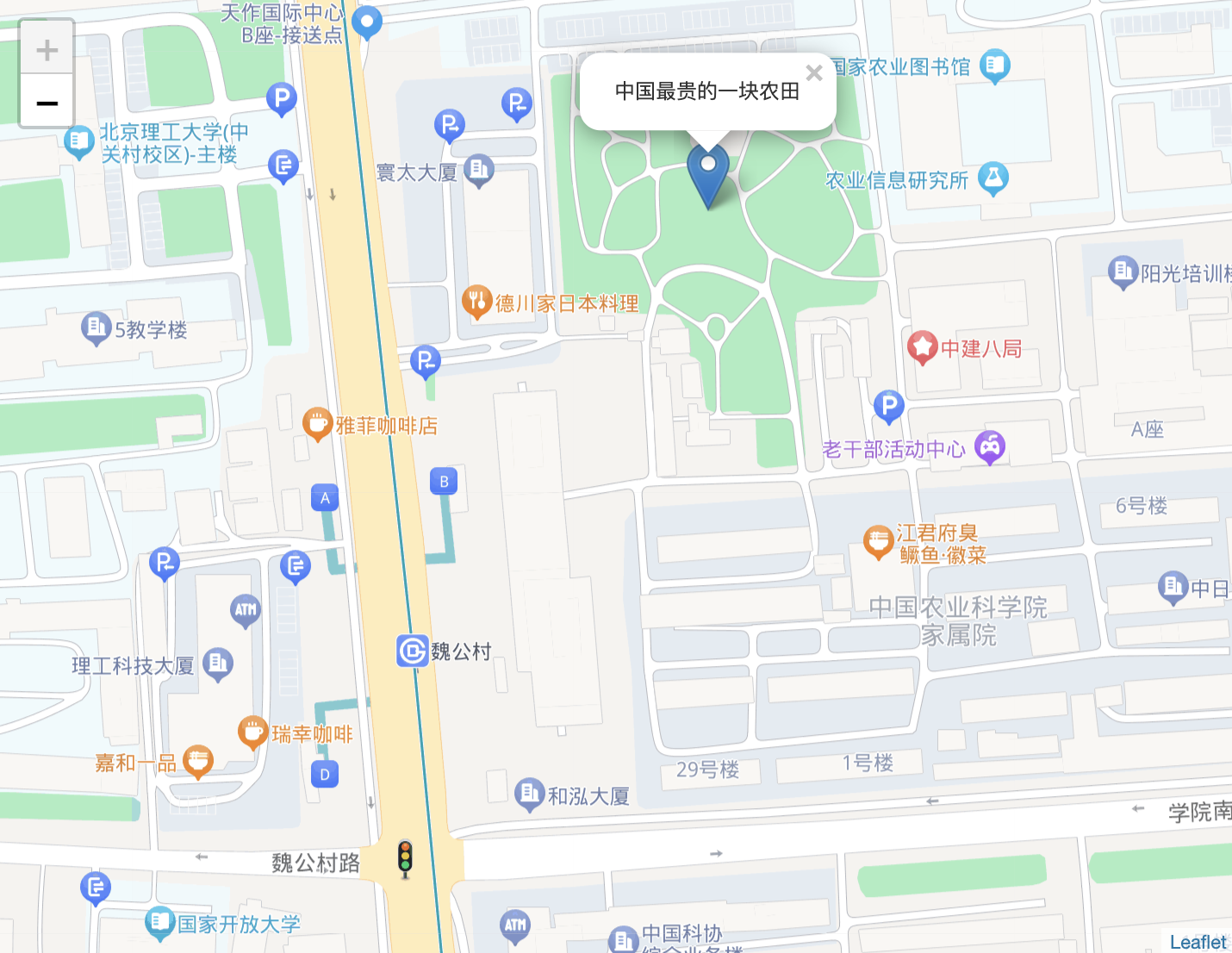
7. 工具和解决方案
前面简要的介绍了和时空相关的一些基础知识,利用 R 作为工具做了一些演示。实际上时空数据包含了至少存储、计算、可视化、模型四部分。如果想省心,可以转向最成熟的商业软件 ArcGIS,如果工作只是涉及其中的一部分,也有不同的开源的工具可以使用,成体系的有 Apache 协议下的 GeoMesa、Sedona(支持分布式,个人比较推荐),下图是 Sedona 的系统架构图:

如果工作只是一部分涉及的话,可以单独看解决方案:
- 存储:PostGIS、redis
- 计算:JTS、GEOS、R(wrapper)、Python(wrapper)
- 可视化:一般都是 JS 框架,如 Leaflet(乌克兰作者,愿战争远离我们每个人)、deck.gl 等
- 模型:建议先用 R、Python 跑通,这个体系太庞大,看如果有空我再单独写一篇。
8. 回到开始的问题
基于以上获得地球上任意物体的坐标的讨论,可以推断地球人没法给三体人发送自己的坐标,大刘的这个设定存在问题。
理由如下:
- 宇宙中地球的位置需要有一个参照系,这个参照系显然需要“三体人”给我们,这样我们才能给出”合理“的位置数据(参考火星坐标系现象)。
- 要计算地球的位置,需要有若干个发射源不停地广播自己的位置,地球进行接收(参考 GPS 原理)。地球人显然不知道这个广播源在哪里,从能量损耗角度讲,除非人类知道三体人的方向,朝着那个方向发射过去,才有可能接收到表示位置的能量。
- 以及通讯的文字解码也是个问题。
如果三体人获得了地球的坐标,那么大概率会使用空间 H3 的类似技术快速锁定我们从属的区域(空间检索),甚至做一些空间拓扑关系的运算(从属区域历史上还有没有报告坐标的生命体,有几个?)。最后通过类似墨卡托投影的技术,把地球投影在星图上。
要解决这些问题必须要说明白宇宙的中心在哪里,这样后面就可以一步一步解决了。那宇宙的中心在哪里呢?两脚兽有个说法——宇宙的中心在铁岭。
一本正经地胡说八道完毕。
参考文献: