90 行代码实现问答型商品推荐系统
本文可以帮助大家理解 ChatGPT 这类的大语言模型是如何在我们的日常生活中发挥作用。
1. 解决的是什么问题?
假如你叫刘弱(强)西(东),现在经营一家售卖食品的电商平台 Bmazon,拥有 70000 件各类食品(包括零食、糕点、巧克力、糖果、猫粮、狗粮……)。这些商品对应有自己的描述和顾客购买使用后的评价。如果有一个机器人,它能通过和客户对话,总结顾客的潜在购买意图,给出推荐商品。这样聪明的机器人能不能来一个呢?
先随便来一个用户购买咨询:
有什么好吃的坚果推荐购买吗?
先别看答案,闭上眼睛暂停十秒钟!如果你是客服导购,你会怎么回答?
....
这个机器人这样回答的:
这些商品是各类坚果产品,包括混合坚果、坚果棒和单品种坚果如碧根果和夏威夷果等。它们的特点是:品质上乘,口感绝佳,深受大人小孩喜爱;部分产品采用完美配比,融合了杏仁、蜂蜜烤花生、芝麻棒、黑巧克力裹 soy 坚果以及软糯的核桃和山核桃,甜度适中;部分坚果无盐且新鲜美味,特别适合健康饮食需求,如控制血压者食用;有些产品提供大包装,经济实惠;还有自制混合坚果与干果,适合早餐搭配,营养丰富。另外,部分品牌因其出色的产品线和快速免费送货服务而受到高度推荐。总体而言,这些坚果产品不仅美味可口,还具有多种健康益处,是聚会、节日礼物或日常零食的理想选择。
以及相关的商品推荐,您可以在 Bmazon 上购买:
- Planters Trail Mix, Energy Mix
- Eat Natural Bars: Almond & Raisin with Brazil Nuts & Peanuts
- Planters Mixed Nuts, Antioxidant Mix
这三款产品,它们长这个样子:

是不是很神奇?这个问答型引擎可以用 90 行代码实现。喔?有点意思……且听我讲讲如何实现。
2. 原料准备
我们要构建一个问答型的商品推荐系统,领域内的文本(知识)是关键。知乎上的问答显然无法支撑这个想法,亚马逊的商品评论数据是很好的选择。当有了这些文本数据后,领域内的信息互动就能够做到了(用户的咨询可以找到相似的评论文本)。除此之外,还需要一个对话模型,可以将信息组织成人理解的语言。也就是说,需要两个关键原料:
- 本地知识库:选用了 Amazon 在 1999 - 2012 年 25 万用户在 7 万食物商品上的 56 万条评论详情。
- 可调用的高性能的大语言模型:阿里通义千问的 720 亿参数规模的 Qwen-72B。这是笔者对比了 OpenAI、本地部署、国产大模型……之后的选择,过程不做赘述。
2.1. Amazon 的购买行为数据
稍稍瞄一眼,原始的数据长啥样:
| Id | ProductId | UserId | ProfileName | Score | Time |
|---|---|---|---|---|---|
| 1 | B001E4KFG0 | A3SGXH7AUHU8GW | delmartian | 5 | 1303862400 |
| 2 | B00813GRG4 | A1D87F6ZCVE5NK | dll pa | 1 | 1346976000 |
| 3 | B000LQOCH0 | ABXLMWJIXXAIN | Natalia Corres ""Natalia Corres"" | 4 | 1219017600 |
| 4 | B000UA0QIQ | A395BORC6FGVXV | Karl | 2 | 1307923200 |
| 5 | B006K2ZZ7K | A1UQRSCLF8GW1T | Michael D. Bigham ""M. Wassir"" | 5 | 1350777600 |
| 6 | B006K2ZZ7K | ADT0SRK1MGOEU | Twoapennything | 4 | 1342051200 |
以及我们最关心的评论文本。ID = 1 的用户是这么评价:
I have bought several of the Vitality canned dog food products and have found them all to be of good quality. The product looks more like a stew than a processed meat and it smells better. My Labrador is finicky and she appreciates this product better than most.
ID = 2 的用户的评价文本是这样:
Product arrived labeled as Jumbo Salted Peanuts...the peanuts were actually small sized unsalted. Not sure if this was an error or if the vendor intended to represent the product as ""Jumbo"".
细扒的话,会发现用户评论信息内存在大量非英文字符,以及超链接文本。用正则表达式处理成纯文本是其中的一个小步骤。
2.2. 阿里通义千问大模型
国产大模型孰优孰劣不好评价,市面上也有很多评测标准,基本上各家都会找到有利于自己的一些测评结果,反正大家都是第一。从本质上看的话,数据集多样性和丰富度、计算资源(算力)、模型架构和算法技巧(工程师能力)四个方面是关键要素。从调用方式上判断,阿里通义大语言模型更适合我的工作环境,因为调用接口仅需要安装 Python 的一个包:
pip3 install dashscope
引入 dashscope 之后,核心是一个 Call 函数,对应 user 和 content 两个参数。不纠结,这个理由足够。
另外基于我们的这个场景简单比对了一下 Qwen-7B、Qwen-72B、Qwen-Plus、Qwen-Max 效果,参数规模达到千亿级别的 Qwen-Max 表现最好。刚好上周阿里团队到公司有一次交流,详细分享了各类模型使用细节。阿里的产品同事同样也推荐使用 Qwen-Max:效果最优,当然也最贵!Qwen-Max 的 API 调用限定用户输入为 6k tokens,覆盖这个场景绰绰有余。
2.3. 技术框架
实现前文演示的机器人,核心实现步骤只有四个步骤:
- 步骤一:通过 embedding 技术,将所有评论映射到低维向量空间,获得“评论向量”。
- 步骤二:将查询的 Query 利用同样的 embedding 技术,转化为低维 “Query 向量”。
- 步骤三:比对 Query 和评论的相似度(向量相似度),召回最相似评论的集合(Chunks)。
- 步骤四:将这些 Chunks 重新组织成 prompt 丢进大模型里,利用大模型的语言组织能力返回答案,同时返回商品清单。
第 1 步需要提前做好预处理,评论向量的结果用于后续步骤。第 2 步是问答型商品推荐系统用户的问询部分,也是该系统的唯一输入。第 4 步是问答返回的结果,包含了推荐商品的文字内容、商品链接两部分。
2.4. 细节讨论
想象一下用户的问询:
有什么好吃的坚果推荐购买吗?
这里面有这几个关键词:好吃、坚果、推荐、购买。如果用户的意图可以通过这四个词的向量 相加 就好了,甚至用户表达了:我不喜欢混合坚果。那么,“混合”这个词能够用 相减 的方式来处理,那就完美了!要满足这样的设想,源自于斯坦福大学的 GloVe 算法刚好适用。算法细节客官可以参见这里。官网上给了一个通过语料训练得到的词汇关系,直观的体现了 Glove 算法的优雅:
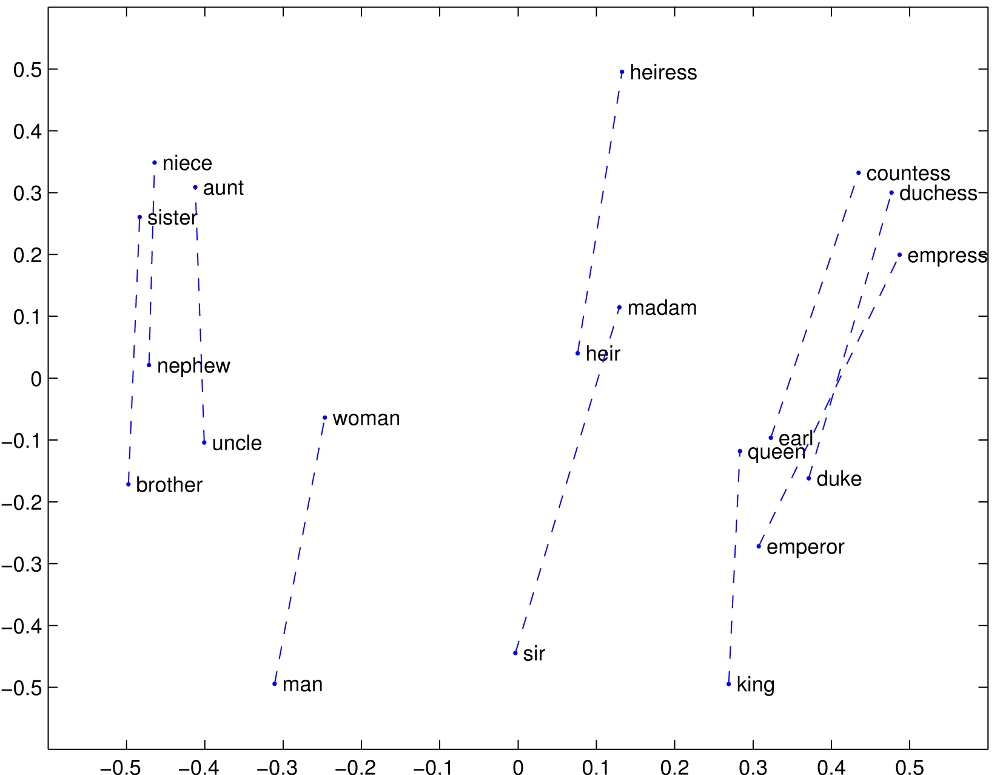
身份、性别、血缘这些概念在二维空间上,非常微妙地组织在了一起。直观的看 man - woman, king - queen, brother - sister 的距离基本是相等的,也就是说:
man - woman = king - queen,那么 queen = king - man + woman!
这个算法原理非常适合这个场景,既然词向量的"加减"代表意义的变化,那么就可以“暴力”地获得句子向量,以及兴趣向量(不是最优,后文有解释)。
3. 关键过程描述
90 行详细代码我放在了全文之后,这里摘取一部分中间的关键过程,用于说明实现细节。
第一部分是通过 GloVe 算法生成的“词向量”,单词的数量有 23000,随便用 6 个单词看看它们前 5 维(总计 50 维)什么样子:
| Word | d1 | d2 | d3 | d4 | d5 |
|---|---|---|---|---|---|
| caloriesbut | 0.5328530 | -0.1984420 | 0.2264205 | -1.0080164 | 0.5556314 |
| caloriesthey | 0.0441083 | -0.0377092 | 0.7923388 | 0.3361781 | -0.2935881 |
| cameron | 0.3276865 | 0.6343640 | 0.4496154 | 0.5232927 | 0.4964200 |
| campari | -0.0778625 | -0.2173479 | 0.7414341 | 0.1315289 | 0.3475144 |
| cancellation | 0.3215747 | 0.3530505 | 0.1590252 | -0.1406696 | 0.8450537 |
| cannery | -0.1270566 | 0.7451063 | -0.2597326 | 0.3438343 | 0.2620469 |
第二部分是“评论向量”。如前文描述,利用 GloVe 算法,整段评论可以表达为“词向量”的“加和”。随机选取 5 组评论对应的“评论向量”(仅取了前 5 维,总计 50 维):
| Doc ID | d1 | d2 | d3 | d4 | d5 |
|---|---|---|---|---|---|
| 1 | -14.447007 | 3.1292817 | -0.3561071 | -0.9769334 | -2.860675 |
| 2 | -3.222029 | -4.7744274 | -3.7621354 | 0.3966443 | 1.386935 |
| 3 | 2.763255 | -9.1535688 | -7.3250024 | 2.7009571 | -12.357563 |
| 4 | -1.442423 | -0.1724862 | -4.4917097 | 5.1961193 | -5.733810 |
| 5 | -2.280725 | -4.8218712 | -7.2149368 | 2.8688157 | -1.977257 |
基于以上两部分,就可以找到用户发起 query 的相似评论。
回到文章最初用户的提问:有什么好吃的坚果推荐购买吗?根据 delicious, nuts, recommended, buy 四个单词召回的最相似评论有(前 4 个):
[1] "these nuts are the best great large size bag for partys really the best nuts i have ever eaten highly reccommend"
[2] "these nuts are delicious i am so happy they are available in bulk too i highly recommend them try these"
[3] "definitely will be buying more of these peanuts as they are the best freshest peanuts i have ever enjoyed unsalted which is the only way to eat peanuts as when you get them in the shell there is no salt besides you get up there in years and your bp will pay the price for all that salty food these are unsalted and absolutely the best excellent choice for a birthday or christmasholiday gift as well as no one would expect to receive these large crunchy peanuts just outstanding superb"
[4] "these almonds are outstanding every single nut was fresh and crunchy almonds are really good for you and these are a great bargain ill be buying these often"
第 3 个评论中并未出现 nuts,而是在说 peanuts,但 GloVe 算法依然识别了这些概念之间的相似性。以及第 4 条评论的 nut 约等于了 nuts,buying 约等于了 buy。
把这些文本评论,拼接在下段话之后。同时向大模型发问(Prompt 工程):
下面的英文由多款商品的评论构成,请将这些商品的特性做一个中文总结,字数不超过 150 字:
阿里通义千问大模型 Qwen-Max 就会返回人类能够理解,且非常精炼的总结性陈述:
这些商品是各类坚果产品,包括混合坚果、坚果棒和单品种坚果如碧根果和夏威夷果等。它们的特点是:品质上乘,口感绝佳,深受大人小孩喜爱;部分产品采用完美配比,融合了杏仁、蜂蜜烤花生、芝麻棒、黑巧克力裹 soy 坚果以及软糯的核桃和山核桃,甜度适中;部分坚果无盐且新鲜美味,特别适合健康饮食需求,如控制血压者食用;有些产品提供大包装,经济实惠;还有自制混合坚果与干果,适合早餐搭配,营养丰富。另外,部分品牌因其出色的产品线和快速免费送货服务而受到高度推荐。总体而言,这些坚果产品不仅美味可口,还具有多种健康益处,是聚会、节日礼物或日常零食的理想选择。
当然既然评论已经能够找到了,对应的推荐商品内容也就出来了。
4. 已有的现成技术方案
本文实际借鉴了大模型构建本地知识助手的思路,典型的代表是Langchain-ChatGLM。这个项目实现原理如下图所示,过程包括 15 个步骤:
加载文件 -> 读取文本 -> 文本分割 -> 文本向量化 -> 问句向量化 -> 在文本向量中匹配出与问句向量最相似的 top k个 -> 匹配出的文本作为上下文和问题一起添加到 prompt中 -> 提交给 LLM 生成回答
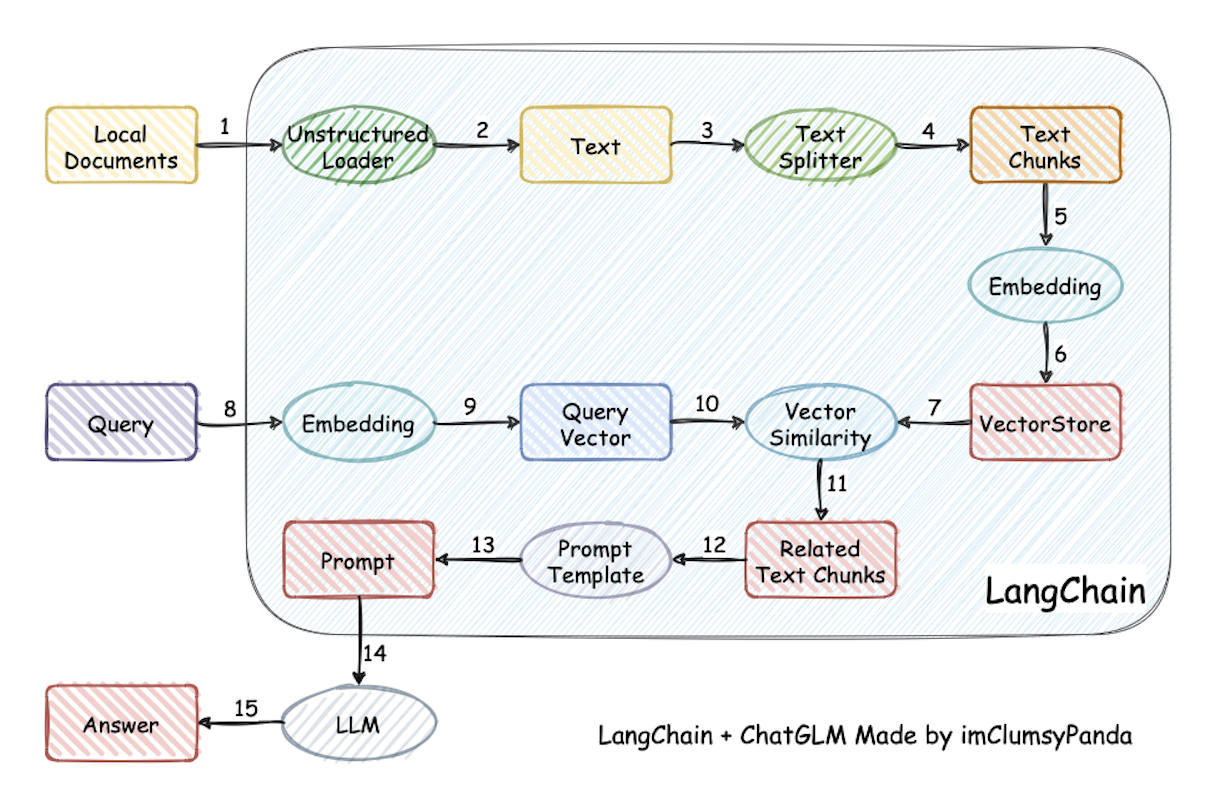
实际上同“问答型商品推荐系统”的方案是完全一致的,各自对应关系:
- 1-2-3-4-5-6-7 对应步骤一,评论的向量化;
- 8-9-10 对应步骤二,Query 的向量化;
- 11-12-13 对应步骤三,返回评论的 Chunks;
- 14-15 对应步骤四,利用大语言模型返回答案。
各位看官根据本文思路和代码生成一个“基于大语言模型的本地知识助手”也是很轻松的。
5. 工程化讨论
如果看官不是工程师背景,文章到此结束。下面讨论工程效果、性能的一些细节问题。
5.1. 为什么用 embedding
正常的话,构建本地知识助手有两种可能的技术方向 fine-tuning 和 embedding。但前者需要的硬件资源巨大,即便是用云端的资源,也需要在开源大模型基础上再训练,要么用自己的算法工程师的“人天”,要么买云商算法工程师的“人天”,成本巨大。
相比较下,embedding 的技术框架更为简单,并且还有个无法拒绝的优点:本地知识库时常会有新增或更新,embedding 重新训练模型(向量化)的成本几乎可以忽略不计。
5.2. embedding 的其他可能
可能在第 3 节有客观会有疑问,既然是通过 query 搜索相关文档,我用一个文本搜索的数据库(比如 Lucene)直接创建索引直接搜不就行了吗,为什么非要用 embedding 的技术来做处理?想象一下,我们从文字中感知到的信息除了词汇外,还有语法、语义、情感、情绪、主题、上下文等,这些信息是无法只通过词汇来表达出的。前文中也出现了一些词汇,比如 nuts 和 peanuts, buy 和 buying 这样的效果,embedding 显然效果会更好。
另外还可以直接调用大厂的 embedding 算法直接返回你需要的素材:“评论向量”通过调用接口的方式全部获得后再本地化部署,用户 query 向量可以通过实时接口获得(也可本地部署)。大厂(顶级互联网公司)发布的模型语料更佳丰富、考虑的细节更多,效果更佳。比如这里是一个本地部署文档向量和 Query 向量的例子,方案采用的是 jina.ai开源的的向量化模型:
1 | library(lsa) |
这 8 段文本之间的 两两 cosine 距离是:
| 1.00 | 0.90 | -0.02 | -0.14 | -0.02 | -0.02 | -0.01 | -0.01 |
| 0.90 | 1.00 | -0.04 | -0.14 | 0.02 | -0.08 | -0.07 | -0.06 |
| -0.02 | -0.04 | 1.00 | 0.01 | 0.09 | 0.01 | 0.04 | -0.03 |
| -0.14 | -0.14 | 0.01 | 1.00 | 0.57 | -0.04 | -0.06 | 0.02 |
| -0.02 | 0.02 | 0.09 | 0.57 | 1.00 | -0.21 | -0.20 | -0.04 |
| -0.02 | -0.08 | 0.01 | -0.04 | -0.21 | 1.00 | 0.93 | 0.48 |
| -0.01 | -0.07 | 0.04 | -0.06 | -0.20 | 0.93 | 1.00 | 0.19 |
| -0.01 | -0.06 | -0.03 | 0.02 | -0.04 | 0.48 | 0.19 | 1.00 |
注意,"what is the capital of China?" 和 "Beijing" 的相似度有 0.57,如果只考虑纯粹的文本相似度,相似度是为 0 的。
5.3. 相似度计算
那既然用 embedding 向量化的方式,向量化存储以及相似度计算就是关键问题了。下面的代码实际上就是将“评论向量”放置到了内存中,利用 sim2 函数做了相似度运算(y 是 query 向量)
1 | cos_sim = sim2( |
这点小数据量性能的花销还好,一旦我们为了更复杂的表征,向量维度几千维,评论数量几百亿,存储和计算都是工程难题。不过好在,太阳底下没有新鲜事,前人已经给出非常完备的解决方案,比如
- Faiss:Meta 开源的向量数据库,不必加载到内存,支持欧式距离(L2)和点积(dot product),支持 GPU 计算。
- Milvus:开源的向量数据库,支持云原生。Star 数量 25k,笔者撰文两小时前还有更新,是 OpenAI 官方和微软官方的合作伙伴。
关于为什么这些向量数据库可以这么快,篇幅所限,读者可自行 Google 之。
5.4. 如何处理历史偏好
如果采用 GloVe 训练评论向量的话,可以使用 +- 的关键词的方式处理用户的意图,虽然该算法是基于全局词频统计的方法,但笔者小范围尝试效果是够用的。如果是使用预训练 embedding 模型的话,可以考虑将用户历史上不喜欢的 query 结果缓存,在新的召回中剔除即可。
5.5. 语料中没有的答案
通过点击流记录用户的无返回结果,针对于这些 bad case 增加规则和异常处理逻辑。
刘弱(强)西(东),你兴奋不?创业去吧,哈哈哈~~
6. 实现代码
1 | ## 使用数据 https://www.kaggle.com/datasets/snap/amazon-fine-food-reviews/data |